Models fixed
This commit is contained in:
parent
d8815d46f9
commit
55a7e85f47
12 changed files with 121 additions and 103 deletions
14
README.md
14
README.md
|
|
@ -2,12 +2,14 @@
|
|||
|
||||
### About the Project
|
||||
|
||||
This project has the goal of developing a search engine able to query a large Python code repository using multiple sources of information.
|
||||
This project has the goal of developing a search engine able to query a large Python code repository using multiple
|
||||
sources of information.
|
||||
It is part of the Knowledge Analysis & Management - 2022 course from the Università della Svizzera italiana.
|
||||
|
||||
In this repository, you can find the following files:
|
||||
|
||||
- tensor flow: a code repository to be used during this project
|
||||
- ground-truth-unique: a file containing the references triples necessary to evaluate the search engine (step 3)
|
||||
- ground-truth-unique: a file containing the references triples necessary to evaluate the search engine (step 3)
|
||||
|
||||
For more information, see the Project-02 slides (available on iCourse)
|
||||
|
||||
|
|
@ -65,10 +67,10 @@ performance of the classifiers in terms of average precision and recall, which a
|
|||
|
||||
| Engine | Average Precision | Average Recall |
|
||||
|:---------|:--------------------|:-----------------|
|
||||
| tfidf | 20.00% | 20.00% |
|
||||
| freq | 27.00% | 40.00% |
|
||||
| lsi | 4.00% | 20.00% |
|
||||
| doc2vec | 10.00% | 10.00% |
|
||||
| tfidf | 90.00% | 90.00% |
|
||||
| freq | 93.33% | 100.00% |
|
||||
| lsi | 90.00% | 90.00% |
|
||||
| doc2vec | 73.33% | 80.00% |
|
||||
|
||||
## Report
|
||||
|
||||
|
|
|
|||
Binary file not shown.
{kind=link}
Binary file not shown.
|
Before 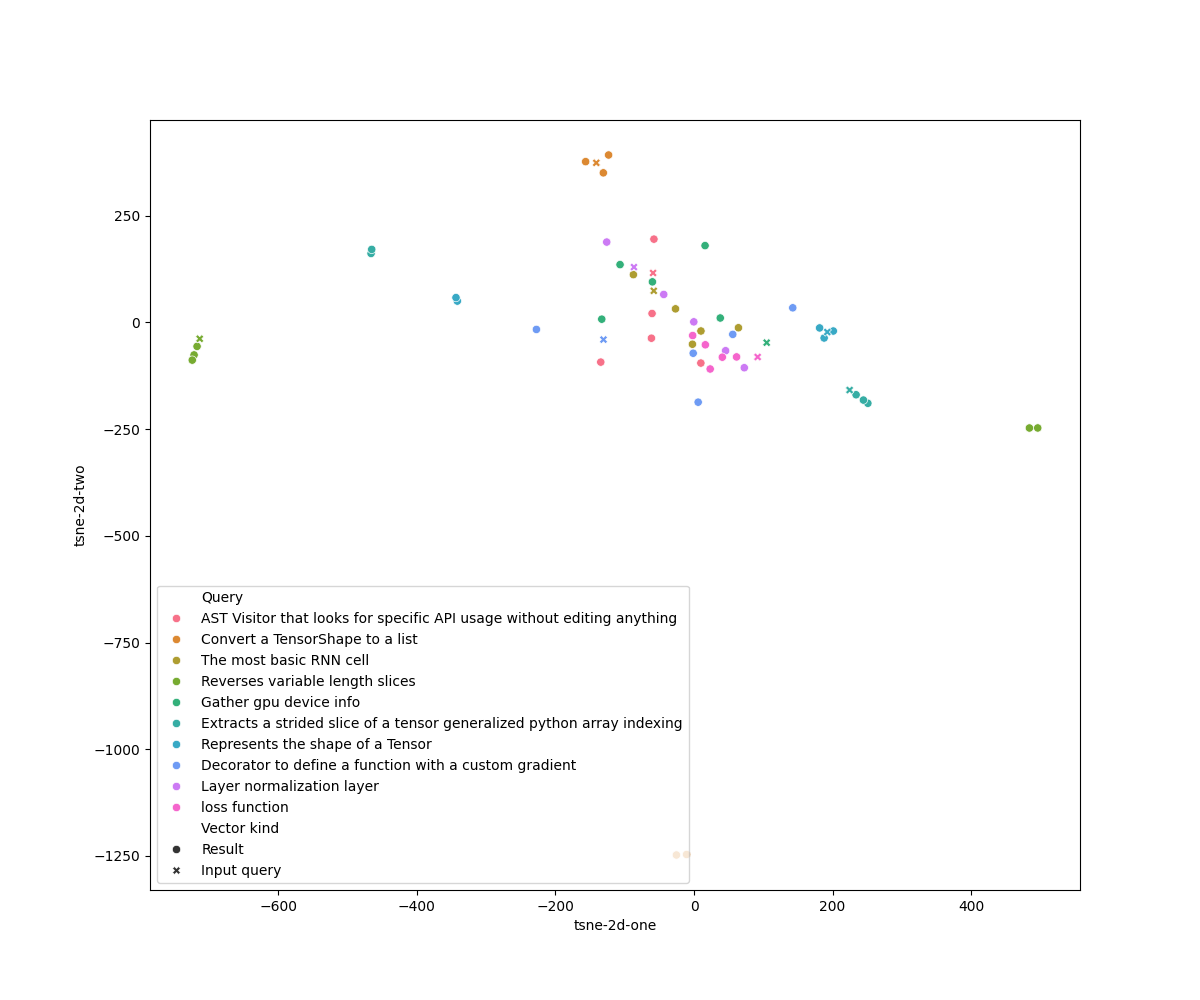
(image error) Size: 77 KiB After 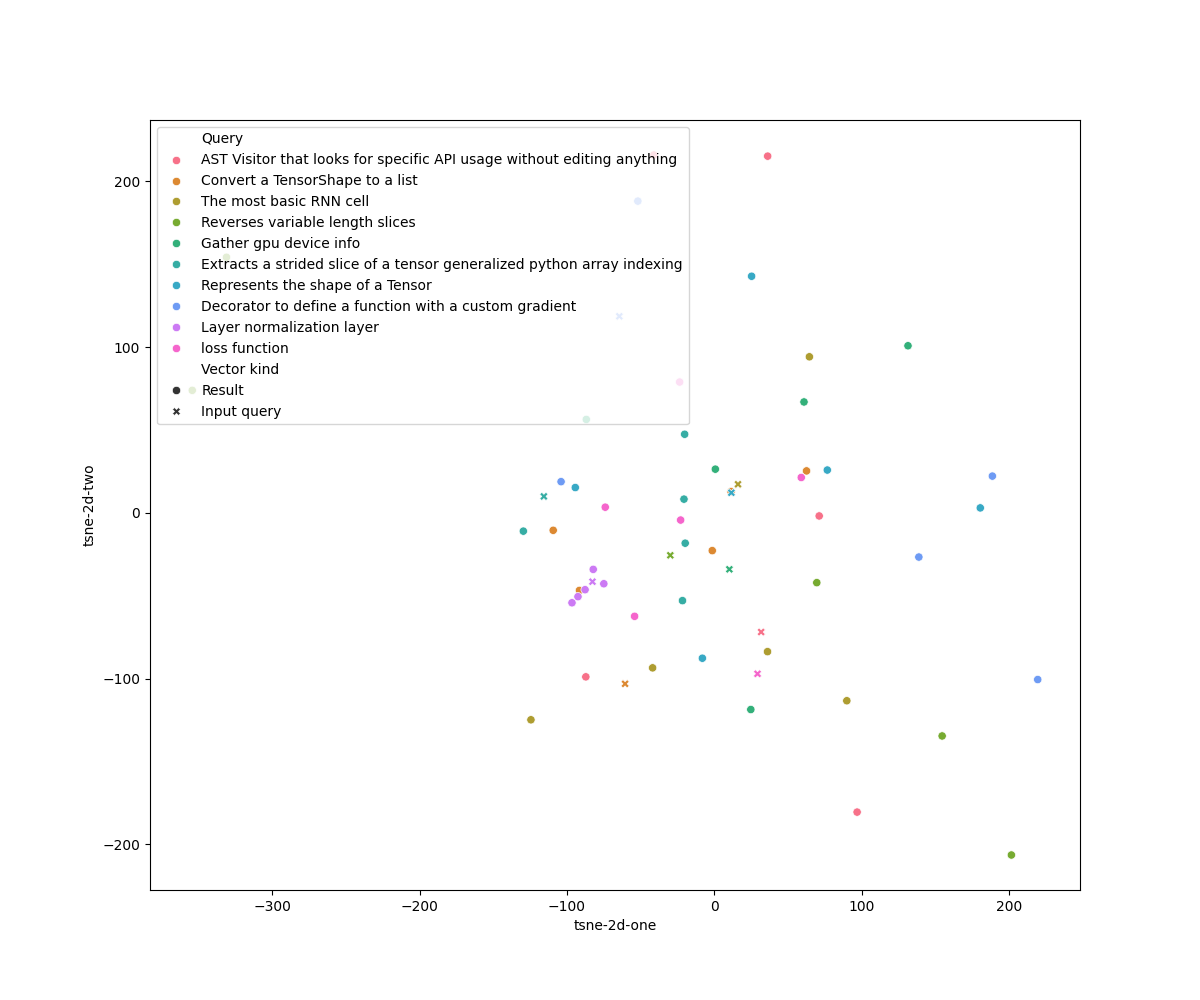
(image error) Size: 76 KiB
|
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 10.00%
|
||||
Recall: 10.00%
|
||||
Precision: 73.33%
|
||||
Recall: 80.00%
|
||||
|
|
|
|||
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 27.00%
|
||||
Recall: 40.00%
|
||||
Precision: 93.33%
|
||||
Recall: 100.00%
|
||||
|
|
|
|||
BIN
out/lsi_plot.png
BIN
out/lsi_plot.png
{kind=link}
Binary file not shown.
|
Before 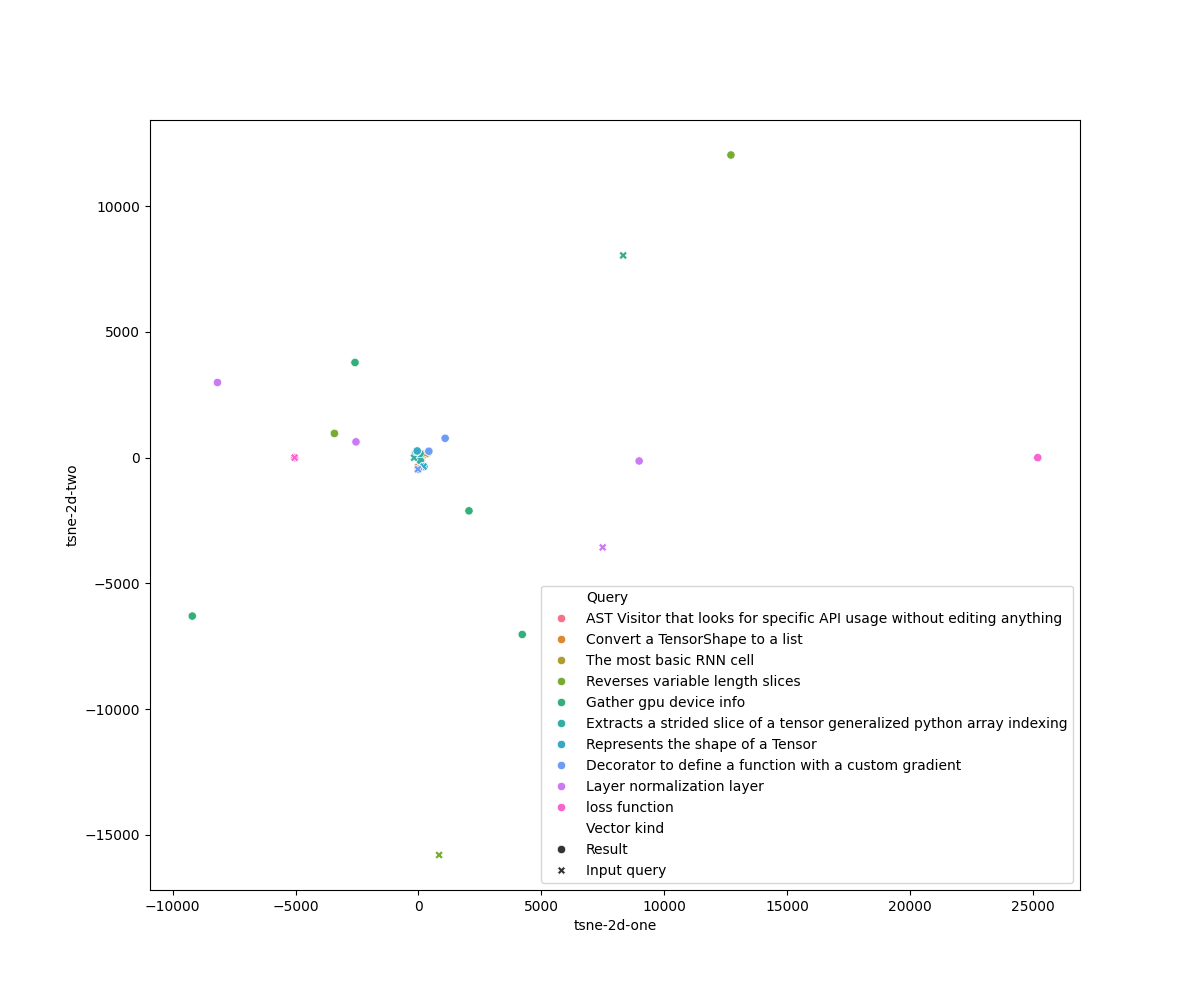
(image error) Size: 71 KiB After 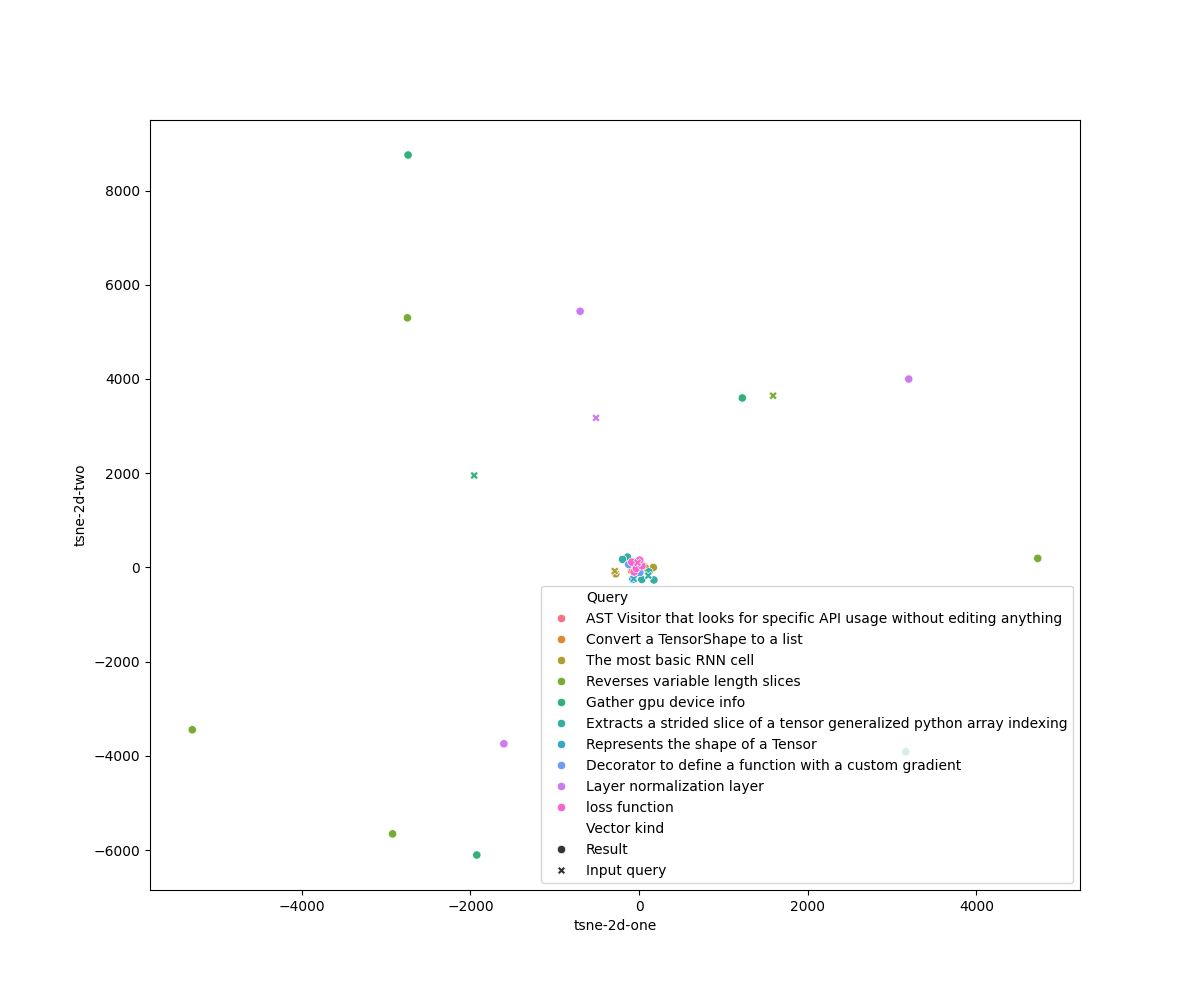
(image error) Size: 72 KiB
|
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 4.50%
|
||||
Recall: 20.00%
|
||||
Precision: 90.00%
|
||||
Recall: 90.00%
|
||||
|
|
|
|||
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 20.00%
|
||||
Recall: 20.00%
|
||||
Precision: 90.00%
|
||||
Recall: 90.00%
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ def better_index(li: list[tuple[int, float]], e: int) -> Optional[int]:
|
|||
def plot_df(results, query: str) -> Optional[pd.DataFrame]:
|
||||
if results.vectors is not None and results.query_vector is not None:
|
||||
tsne_vectors = np.array(results.vectors + [results.query_vector])
|
||||
tsne = TSNE(n_components=2, perplexity=1, n_iter=3000)
|
||||
tsne = TSNE(n_components=2, perplexity=2, n_iter=3000)
|
||||
tsne_results = tsne.fit_transform(tsne_vectors)
|
||||
df = pd.DataFrame(columns=['tsne-2d-one', 'tsne-2d-two', 'Query', 'Vector kind'])
|
||||
df['tsne-2d-one'] = tsne_results[:, 0]
|
||||
|
|
|
|||
BIN
report/main.pdf
BIN
report/main.pdf
Binary file not shown.
171
report/main.tex
171
report/main.tex
|
|
@ -71,6 +71,10 @@ Methods & 5817 \\
|
|||
\subsection*{Section 2: Training of search engines}
|
||||
|
||||
The training and model execution of the search engines is implemented in the Python script \texttt{search-data.py}.
|
||||
The training model loads the data extracted by \texttt{extract-data.py} and uses as classification features the
|
||||
identifier name and only the first line of the comment docstring. All other comment lines are filtered out as this
|
||||
significantly increases performance when evaluating the models.
|
||||
|
||||
The script is able to search a given natural language query among the extracted TensorFlow corpus using four techniques.
|
||||
These are namely: Word Frequency Similarity, Term-Frequency Inverse Document-Frequency (TF-IDF) Similarity, Latent
|
||||
Semantic Indexing (LSI), and Doc2Vec.
|
||||
|
|
@ -78,42 +82,41 @@ Semantic Indexing (LSI), and Doc2Vec.
|
|||
An example output of results generated from the query ``Gather gpu device info'' for the word frequency, TF-IDF, LSI
|
||||
and Doc2Vec models are shown in
|
||||
figures~\ref{fig:search-freq},~\ref{fig:search-tfidf},~\ref{fig:search-lsi}~and~\ref{fig:search-doc2vec} respectively.
|
||||
Both the word frequency and TF-IDF model identify the correct result (according to the provided ground truth for this
|
||||
query) as the first recommendation to output. Both the LSI and Doc2Vec models fail to report the correct function in
|
||||
all 5 results.
|
||||
All four models are able to correctly report the ground truth required by the file \texttt{ground-truth-unique.txt} as
|
||||
the first result with $>90\%$ similarity, with the except of the Doc2Vec model which reports $71.63\%$ similarity.
|
||||
|
||||
\begin{figure}[b]
|
||||
\small
|
||||
\begin{verbatim}
|
||||
Similarity: 87.29%
|
||||
Similarity: 90.45%
|
||||
Python function: gather_gpu_devices
|
||||
Description: Gather gpu device info. Returns: A list of test_log_pb2.GPUInf...
|
||||
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||
Line: 167
|
||||
|
||||
Similarity: 60.63%
|
||||
Python function: compute_capability_from_device_desc
|
||||
Description: Returns the GpuInfo given a DeviceAttributes proto. Args: devi...
|
||||
File: tensorflow/tensorflow/python/framework/gpu_util.py
|
||||
Line: 35
|
||||
|
||||
Similarity: 60.30%
|
||||
Python function: gpu_device_name
|
||||
Description: Returns the name of a GPU device if available or the empty str...
|
||||
File: tensorflow/tensorflow/python/framework/test_util.py
|
||||
Line: 129
|
||||
|
||||
Similarity: 58.83%
|
||||
Python function: gather_available_device_info
|
||||
Description: Gather list of devices available to TensorFlow. Returns: A lis...
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 126
|
||||
|
||||
Similarity: 57.74%
|
||||
Python function: gather_memory_info
|
||||
Description: Gather memory info.
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 70
|
||||
|
||||
Similarity: 57.74%
|
||||
Python function: gather_platform_info
|
||||
Description: Gather platform info.
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 146
|
||||
|
||||
Similarity: 55.47%
|
||||
Python function: compute_capability_from_device_desc
|
||||
Description: Returns the GpuInfo given a DeviceAttributes proto. Args: devi...
|
||||
File: tensorflow/tensorflow/python/framework/gpu_util.py
|
||||
Line: 35
|
||||
|
||||
Similarity: 55.47%
|
||||
Python function: gather_available_device_info
|
||||
Description: Gather list of devices available to TensorFlow. Returns: A lis...
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 126
|
||||
\end{verbatim}
|
||||
\caption{Search result output for the query ``Gather gpu device info'' using the word frequency similarity model.}
|
||||
\label{fig:search-freq}
|
||||
|
|
@ -122,33 +125,34 @@ Line: 70
|
|||
\begin{figure}[b]
|
||||
\small
|
||||
\begin{verbatim}
|
||||
Similarity: 86.62%
|
||||
Similarity: 90.95%
|
||||
Python function: gather_gpu_devices
|
||||
Description: Gather gpu device info. Returns: A list of test_log_pb2.GPUInf...
|
||||
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||
Line: 167
|
||||
|
||||
Similarity: 66.14%
|
||||
Similarity: 59.12%
|
||||
Python function: gather_memory_info
|
||||
Description: Gather memory info.
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 70
|
||||
|
||||
Similarity: 62.52%
|
||||
Similarity: 56.40%
|
||||
Python function: gather_available_device_info
|
||||
Description: Gather list of devices available to TensorFlow. Returns: A lis...
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 126
|
||||
|
||||
Similarity: 57.98%
|
||||
Python function: gather
|
||||
File: tensorflow/tensorflow/compiler/tf2xla/python/xla.py
|
||||
Line: 452
|
||||
Similarity: 55.25%
|
||||
Python function: gather_platform_info
|
||||
Description: Gather platform info.
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 146
|
||||
|
||||
Similarity: 57.98%
|
||||
Python function: gather_v2
|
||||
File: tensorflow/tensorflow/python/ops/array_ops.py
|
||||
Line: 4736
|
||||
Similarity: 53.97%
|
||||
Python function: info
|
||||
File: tensorflow/tensorflow/python/platform/tf_logging.py
|
||||
Line: 167
|
||||
\end{verbatim}
|
||||
\caption{Search result output for the query ``Gather gpu device info'' using the TF-IDF model.}
|
||||
\label{fig:search-tfidf}
|
||||
|
|
@ -157,34 +161,34 @@ Line: 4736
|
|||
\begin{figure}[b]
|
||||
\small
|
||||
\begin{verbatim}
|
||||
Similarity: 92.11%
|
||||
Similarity: 98.38%
|
||||
Python function: gather_gpu_devices
|
||||
Description: Gather gpu device info. Returns: A list of test_log_pb2.GPUInf...
|
||||
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||
Line: 167
|
||||
|
||||
Similarity: 97.66%
|
||||
Python function: device
|
||||
Description: Uses gpu when requested and available.
|
||||
File: tensorflow/tensorflow/python/framework/test_util.py
|
||||
Line: 1581
|
||||
|
||||
Similarity: 92.11%
|
||||
Similarity: 97.66%
|
||||
Python function: device
|
||||
Description: Uses gpu when requested and available.
|
||||
File: tensorflow/tensorflow/python/keras/testing_utils.py
|
||||
Line: 925
|
||||
|
||||
Similarity: 89.04%
|
||||
Python function: compute_capability_from_device_desc
|
||||
Description: Returns the GpuInfo given a DeviceAttributes proto. Args: devi...
|
||||
File: tensorflow/tensorflow/python/framework/gpu_util.py
|
||||
Line: 35
|
||||
Similarity: 96.79%
|
||||
Python class: ParallelDevice
|
||||
Description: A device which executes operations in parallel.
|
||||
File: tensorflow/tensorflow/python/distribute/parallel_device/parallel_device.py
|
||||
Line: 42
|
||||
|
||||
Similarity: 85.96%
|
||||
Python class: CUDADeviceProperties
|
||||
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||
Line: 51
|
||||
|
||||
Similarity: 85.93%
|
||||
Python function: gpu_device_name
|
||||
Description: Returns the name of a GPU device if available or the empty str...
|
||||
File: tensorflow/tensorflow/python/framework/test_util.py
|
||||
Line: 129
|
||||
Similarity: 96.67%
|
||||
Python method: get_var_on_device
|
||||
File: tensorflow/tensorflow/python/distribute/packed_distributed_variable.py
|
||||
Line: 90
|
||||
\end{verbatim}
|
||||
\caption{Search result output for the query ``Gather gpu device info'' using the LSI model.}
|
||||
\label{fig:search-lsi}
|
||||
|
|
@ -193,30 +197,35 @@ Line: 129
|
|||
\begin{figure}[b]
|
||||
\small
|
||||
\begin{verbatim}
|
||||
Similarity: 81.85%
|
||||
Python method: benchmark_gather_nd_op
|
||||
File: tensorflow/tensorflow/python/kernel_tests/gather_nd_op_test.py
|
||||
Line: 389
|
||||
Similarity: 71.63%
|
||||
Python function: gather_gpu_devices
|
||||
Description: Gather gpu device info. Returns: A list of test_log_pb2.GPUInf...
|
||||
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||
Line: 167
|
||||
|
||||
Similarity: 81.83%
|
||||
Python function: gather_hostname
|
||||
Similarity: 66.71%
|
||||
Python function: device
|
||||
Description: Uses gpu when requested and available.
|
||||
File: tensorflow/tensorflow/python/keras/testing_utils.py
|
||||
Line: 925
|
||||
|
||||
Similarity: 65.23%
|
||||
Python function: gpu_device_name
|
||||
Description: Returns the name of a GPU device if available or the empty str...
|
||||
File: tensorflow/tensorflow/python/framework/test_util.py
|
||||
Line: 129
|
||||
|
||||
Similarity: 64.33%
|
||||
Python function: gather_available_device_info
|
||||
Description: Gather list of devices available to TensorFlow. Returns: A lis...
|
||||
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||
Line: 66
|
||||
Line: 126
|
||||
|
||||
Similarity: 81.07%
|
||||
Python method: benchmarkNontrivialGatherAxis1XLA
|
||||
File: tensorflow/tensorflow/compiler/tests/gather_test.py
|
||||
Line: 210
|
||||
|
||||
Similarity: 80.53%
|
||||
Python method: benchmarkNontrivialGatherAxis4
|
||||
File: tensorflow/tensorflow/compiler/tests/gather_test.py
|
||||
Line: 213
|
||||
|
||||
Similarity: 80.45%
|
||||
Python method: benchmarkNontrivialGatherAxis4XLA
|
||||
File: tensorflow/tensorflow/compiler/tests/gather_test.py
|
||||
Line: 216
|
||||
Similarity: 64.29%
|
||||
Python method: hosts
|
||||
Description: A list of device names for CPU hosts. Returns: A list of devic...
|
||||
File: tensorflow/tensorflow/python/tpu/tpu_embedding.py
|
||||
Line: 1011
|
||||
\end{verbatim}
|
||||
\caption{Search result output for the query ``Gather gpu device info'' using the Doc2Vec model.}
|
||||
\label{fig:search-doc2vec}
|
||||
|
|
@ -227,9 +236,9 @@ Line: 216
|
|||
The evaluation over the given ground truth to compute precision, recall, and the T-SNE plots is performed by the script
|
||||
\texttt{prec-recall.py}. The calculated average precision and recall values are reported in table~\ref{tab:tab2}.
|
||||
|
||||
Precision and recall is quite low for all models, less so for the word frequency and the TF-IDF models.
|
||||
The word frequency model has the highest precision and recall (27\% and 40\% respectively), while the LSI model has the
|
||||
lowest precision (4\%) and Doc2Vec has the lowest recall (10\%).
|
||||
Precision and recall are quite high for all models.
|
||||
The word frequency model has the highest precision and recall ($93.33\%$ and $100.00\%$ respectively), while the Doc2Vec
|
||||
model has the lowest precision ($73.33\%$) and lowest recall ($80.00\%$).
|
||||
|
||||
\begin{table}[H]
|
||||
\centering
|
||||
|
|
@ -237,10 +246,10 @@ lowest precision (4\%) and Doc2Vec has the lowest recall (10\%).
|
|||
\hline
|
||||
Engine & Avg Precision & Recall \\
|
||||
\hline
|
||||
Frequencies & 27.00\% & 40.00\% \\
|
||||
TD-IDF & 20.00\% & 20.00\% \\
|
||||
LSI & 4.00\% & 20.00\% \\
|
||||
Doc2Vec & 10.00\% & 10.00\% \\
|
||||
Frequencies & 93.33\% & 100.00\% \\
|
||||
TD-IDF & 90.00\% & 90.00\% \\
|
||||
LSI & 90.00\% & 90.00\% \\
|
||||
Doc2Vec & 73.33\% & 80.00\% \\
|
||||
\hline
|
||||
\end{tabular}
|
||||
\caption{Evaluation of search engines.}
|
||||
|
|
@ -249,11 +258,13 @@ Doc2Vec & 10.00\% & 10.00\% \\
|
|||
|
||||
\subsection*{TBD Section 4: Visualisation of query results}
|
||||
|
||||
The two-dimensional T-SNE plots (computed with perplexity $= 1$) for the LSI and Doc2Vec models are respectively in
|
||||
The two-dimensional T-SNE plots (computed with perplexity $= 2$) for the LSI and Doc2Vec models are respectively in
|
||||
figures~\ref{fig:tsne-lsi}~and~\ref{fig:tsne-doc2vec}.
|
||||
|
||||
The T-SNE plot for the LSI model shows evidently the presence of outliers in the search result. The Doc2Vec plot shows
|
||||
fewer outliers and more distinct clusters for the results of each query and the query vector itself.
|
||||
fewer outliers and more distinct clusters for the results of each query and the query vector itself. However, even
|
||||
considering the good performance for both models, it is hard to distinguish from the plots given distinct ``regions''
|
||||
where results and their respective query are located.
|
||||
|
||||
\begin{figure}
|
||||
\begin{center}
|
||||
|
|
|
|||
|
|
@ -25,9 +25,7 @@ DOC2VEC_MODEL = os.path.join(SCRIPT_DIR, "doc2vec_model.dat")
|
|||
|
||||
# using nltk stop words and example words for now
|
||||
STOP_WORDS = set(stopwords.words('english')) \
|
||||
.union(['test', 'tests', 'main', 'this', 'self', 'def', 'object', 'false', 'class', 'tuple', 'use', 'default',
|
||||
'none', 'dtype', 'true', 'function', 'returns', 'int', 'get', 'set', 'new', 'return', 'list', 'python',
|
||||
'numpy', 'type', 'name'])
|
||||
.union(['test', 'tests', 'main', 'this', 'self', 'int', 'get', 'set', 'new', 'return', 'list'])
|
||||
|
||||
|
||||
def find_all(regex: str, word: str, lower=True) -> list[str]:
|
||||
|
|
@ -44,7 +42,14 @@ def identifier_split(identifier: str) -> list[str]:
|
|||
return [y for x in identifier.split("_") for y in camel_case_split(x)]
|
||||
|
||||
|
||||
def comment_split(comment: str) -> list[str]:
|
||||
def comment_split(comment: Optional[float | str], is_comment=True) -> list[str]:
|
||||
if (type(comment) == float and np.isnan(comment)) or comment is None:
|
||||
return []
|
||||
|
||||
# Consider only first line of each comment. Increases performance significantly
|
||||
if is_comment:
|
||||
comment = str(comment).split("\n", maxsplit=2)[0]
|
||||
|
||||
# Camel case split within "words" found takes care of referenced type names in the docstring comment
|
||||
return [s for word in find_all('[A-Za-z]+', comment, lower=False) for s in camel_case_split(word)]
|
||||
|
||||
|
|
@ -85,7 +90,7 @@ def print_results(indexes_scores: list[tuple[int, float]], df):
|
|||
.format(feat=row["type"], name=row["name"], desc=desc, file=row["file"], line=row["line"]))
|
||||
|
||||
|
||||
def build_doc2vec_model(corpus_list):
|
||||
def train_doc2vec(corpus_list):
|
||||
dvdocs = [TaggedDocument(text, [i]) for i, text in enumerate(corpus_list)]
|
||||
model = Doc2Vec(vector_size=300, epochs=50, sample=0)
|
||||
model.build_vocab(dvdocs)
|
||||
|
|
@ -145,7 +150,7 @@ def search(query: str, method: str, df: pd.DataFrame) -> SearchResults:
|
|||
document_words = row["name_bow"] + row["comment_bow"]
|
||||
corpus_list.append(document_words)
|
||||
|
||||
query_w = get_bow(query, comment_split)
|
||||
query_w = comment_split(query, is_comment=False)
|
||||
dictionary = None
|
||||
corpus_bow = None
|
||||
query_bow = None
|
||||
|
|
@ -161,7 +166,7 @@ def search(query: str, method: str, df: pd.DataFrame) -> SearchResults:
|
|||
elif method == "freq":
|
||||
return SearchResults(pick_most_similar(corpus_bow, query_bow, dictionary), None, None)
|
||||
elif method == "lsi":
|
||||
lsi = LsiModel(corpus_bow)
|
||||
lsi = LsiModel(corpus_bow, num_topics=50)
|
||||
corpus = typing.cast(list[SparseVector], lsi[corpus_bow])
|
||||
results = pick_most_similar(corpus, lsi[query_bow], dictionary)
|
||||
result_vectors: list[DenseVector] = [to_dense(corpus[idx]) for idx, _ in results]
|
||||
|
|
@ -170,7 +175,7 @@ def search(query: str, method: str, df: pd.DataFrame) -> SearchResults:
|
|||
if os.path.exists(DOC2VEC_MODEL):
|
||||
model = Doc2Vec.load(DOC2VEC_MODEL)
|
||||
else:
|
||||
model = build_doc2vec_model(corpus_list)
|
||||
model = train_doc2vec(corpus_list)
|
||||
|
||||
dv_query = model.infer_vector(query_w)
|
||||
results = model.dv.most_similar([dv_query], topn=5)
|
||||
|
|
|
|||
Loading…
Reference in a new issue