wip report
This commit is contained in:
parent
678434abdf
commit
fd007afb60
13 changed files with 279 additions and 45 deletions
57
README.md
57
README.md
|
|
@ -12,3 +12,60 @@ In this repository, you can find the following files:
|
|||
For more information, see the Project-02 slides (available on iCourse)
|
||||
|
||||
Note: Feel free to modify this file according to the project's necessities.
|
||||
|
||||
## Environment setup
|
||||
|
||||
To install the required dependencies make sure `python3` points to a Python 3.10 or 3.11 installation and then run:
|
||||
|
||||
```shell
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## Part 1: data extraction
|
||||
|
||||
To extract the data in file `data.csv` run the command:
|
||||
|
||||
```shell
|
||||
python3 extract-data.py
|
||||
```
|
||||
|
||||
The script prints the requested counts, which are namely:
|
||||
|
||||
```
|
||||
Methods: 5817
|
||||
Functions: 4565
|
||||
Classes: 1882
|
||||
Python Files: 2817
|
||||
```
|
||||
|
||||
## Part 2: Training
|
||||
|
||||
In order to train and predict the output of a given query run the command:
|
||||
|
||||
```shell
|
||||
python3 search-data.py [method] "[query]"
|
||||
```
|
||||
|
||||
where `[method]` is one of `{tfidf,freq,lsi,doc2vec}` or `all` to run all classifiers and `[query]` is the natural
|
||||
language query to search. Outputs are printed on stdout, and in case of `doc2vec` the trained model file is saved in
|
||||
`./doc2vec_model.dat` and fetched in this path for subsequent executions.
|
||||
|
||||
## Part 3: Evaluation
|
||||
|
||||
To evaluate a model run the command:
|
||||
|
||||
```shell
|
||||
python3 search-data.py [method] ./ground-truth-unique.txt
|
||||
```
|
||||
|
||||
where `[method]` is one of `{tfidf,freq,lsi,doc2vec}` or `all` to evaluate all classifiers. The script outputs the
|
||||
performance of the classifiers in terms of average precision and recall, which are namely:
|
||||
|
||||
| Engine | Average Precision | Average Recall |
|
||||
|:---------|:--------------------|:-----------------|
|
||||
| tfidf | 20.00% | 20.00% |
|
||||
| freq | 27.00% | 40.00% |
|
||||
| lsi | 4.00% | 20.00% |
|
||||
| doc2vec | 10.00% | 10.00% |
|
||||
|
|
|
|||
Binary file not shown.
|
|
@ -15,7 +15,7 @@ def find_py_files(dir):
|
|||
|
||||
|
||||
def keep_name(name):
|
||||
return not name.startswith("_") and not "main" in str(name).lower() and \
|
||||
return not name.startswith("_") and "main" not in str(name).lower() and \
|
||||
"test" not in str(name).lower()
|
||||
|
||||
|
||||
|
|
@ -28,7 +28,7 @@ class FeatureVisitor(ast.NodeVisitor):
|
|||
def visit_FunctionDef(self, node):
|
||||
if keep_name(node.name):
|
||||
self.rows.append({
|
||||
"name": node.name,
|
||||
"name": node.name,
|
||||
"file": self.filename,
|
||||
"line": node.lineno,
|
||||
"type": "function",
|
||||
|
|
@ -56,14 +56,14 @@ class FeatureVisitor(ast.NodeVisitor):
|
|||
})
|
||||
|
||||
|
||||
|
||||
def main():
|
||||
df = pd.DataFrame(columns=["name", "file", "line", "type", "comment"])
|
||||
|
||||
for file in find_py_files(IN_DIR):
|
||||
files = list(find_py_files(IN_DIR))
|
||||
|
||||
for file in files:
|
||||
with open(file, "r") as f:
|
||||
py_source = f.read()
|
||||
|
||||
|
||||
py_ast = ast.parse(py_source)
|
||||
|
||||
visitor = FeatureVisitor(file)
|
||||
|
|
@ -71,6 +71,16 @@ def main():
|
|||
df_visitor = pd.DataFrame.from_records(visitor.rows)
|
||||
df = pd.concat([df, df_visitor])
|
||||
|
||||
counts = df["type"].apply(lambda ft: {
|
||||
"function": "Functions",
|
||||
"class": "Classes",
|
||||
"method": "Methods"
|
||||
}[ft]).value_counts().to_dict()
|
||||
counts["Python Files"] = len(files)
|
||||
|
||||
for file_type, name in counts.items():
|
||||
print(f"{file_type}: {name}")
|
||||
|
||||
df.reset_index(drop=True).to_csv(OUT_FILE)
|
||||
|
||||
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
Before 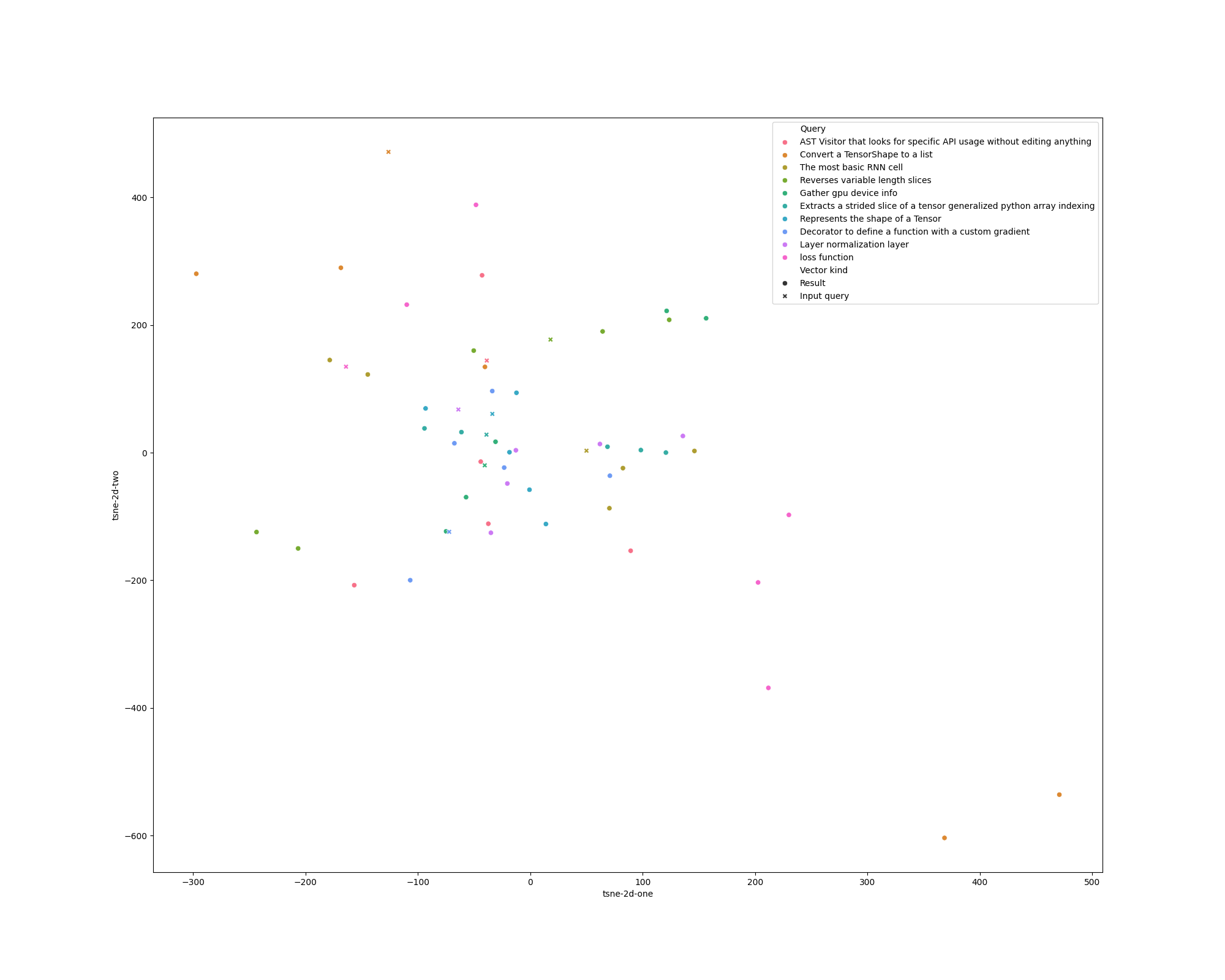
(image error) Size: 89 KiB After 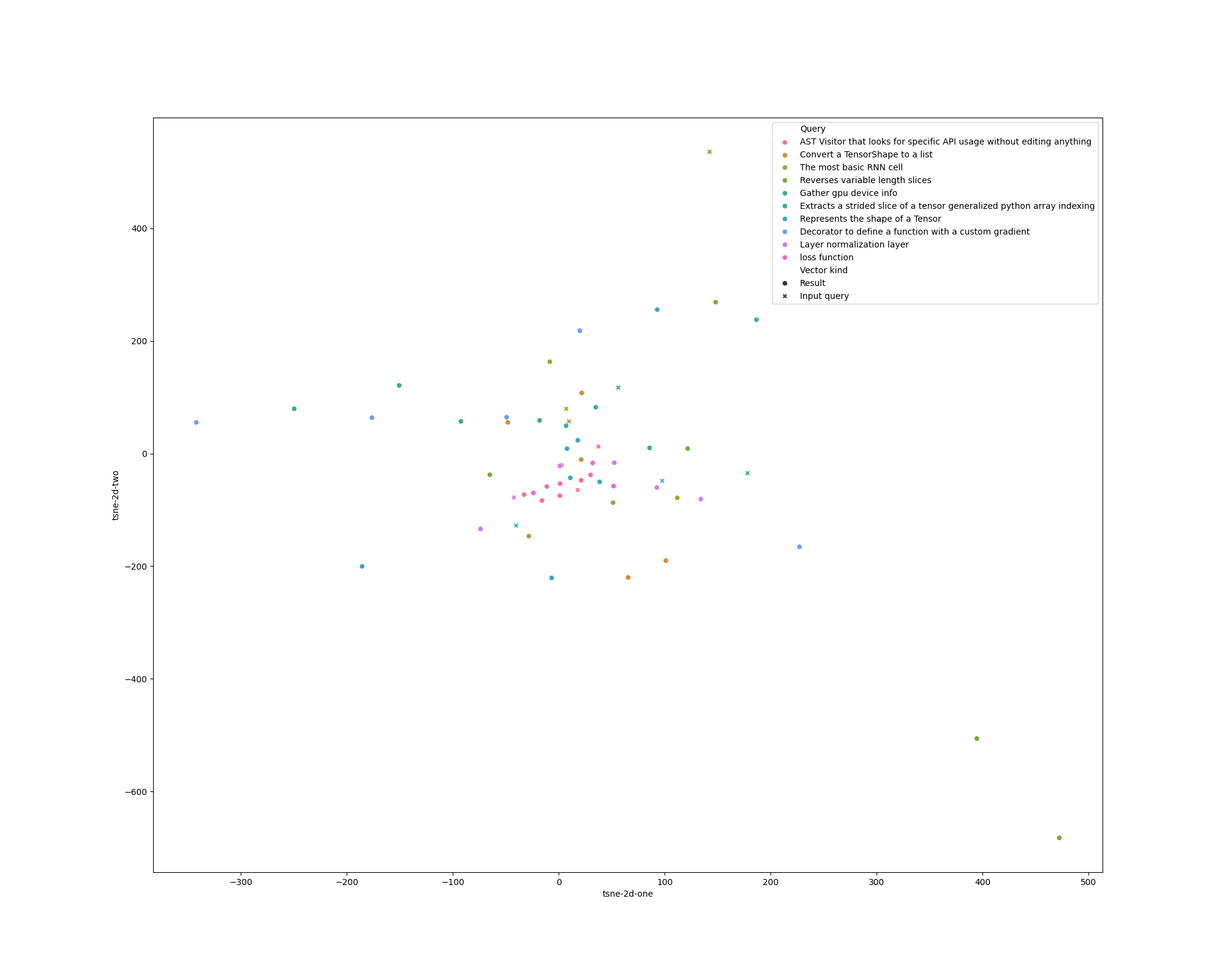
(image error) Size: 89 KiB
|
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 30.00%
|
||||
Recall: 30.00%
|
||||
Precision: 10.00%
|
||||
Recall: 10.00%
|
||||
|
|
|
|||
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 24.50%
|
||||
Recall: 24.50%
|
||||
Precision: 27.00%
|
||||
Recall: 40.00%
|
||||
|
|
|
|||
BIN
out/lsi_plot.png
BIN
out/lsi_plot.png
{kind=link}
Binary file not shown.
|
Before 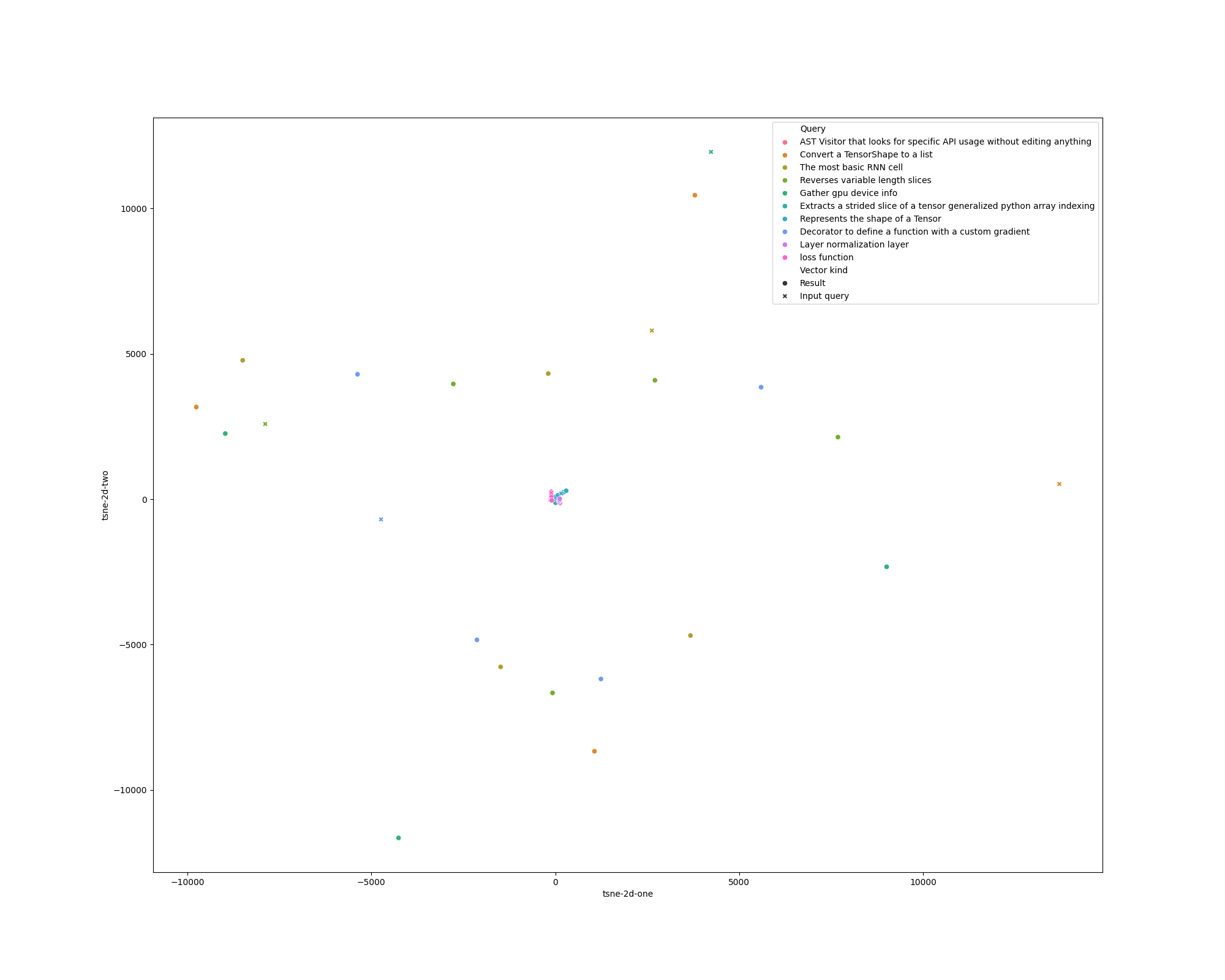
(image error) Size: 82 KiB After 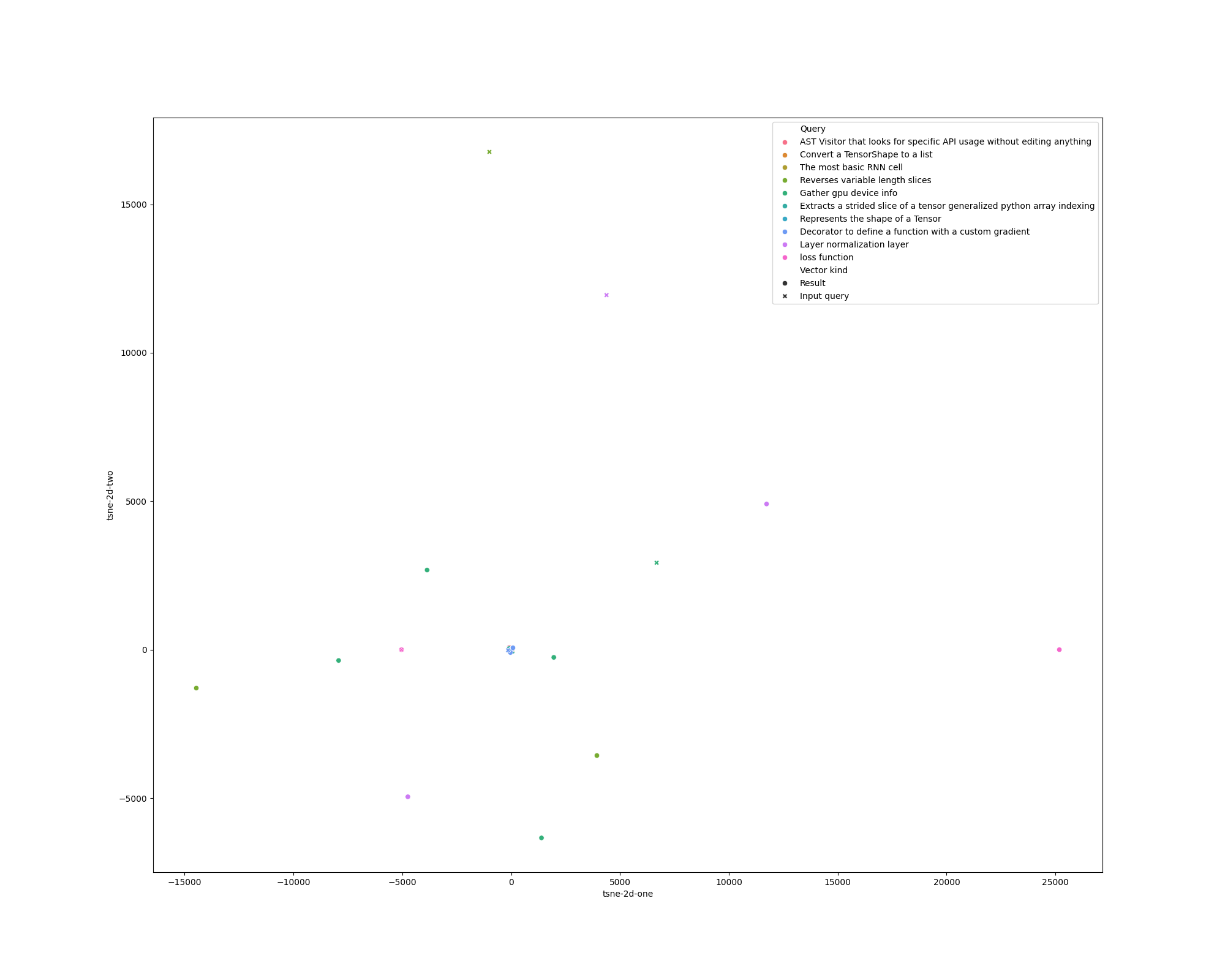
(image error) Size: 79 KiB
|
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 3.33%
|
||||
Recall: 3.33%
|
||||
Precision: 4.00%
|
||||
Recall: 20.00%
|
||||
|
|
|
|||
|
|
@ -1,2 +1,2 @@
|
|||
Precision: 22.50%
|
||||
Recall: 22.50%
|
||||
Precision: 20.00%
|
||||
Recall: 20.00%
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ def better_index(li: list[tuple[int, float]], e: int) -> Optional[int]:
|
|||
def plot_df(results, query: str) -> Optional[pd.DataFrame]:
|
||||
if results.vectors is not None and results.query_vector is not None:
|
||||
tsne_vectors = np.array(results.vectors + [results.query_vector])
|
||||
tsne = TSNE(n_components=2, verbose=1, perplexity=1.5, n_iter=3000)
|
||||
tsne = TSNE(n_components=2, perplexity=2, n_iter=3000)
|
||||
tsne_results = tsne.fit_transform(tsne_vectors)
|
||||
df = pd.DataFrame(columns=['tsne-2d-one', 'tsne-2d-two', 'Query', 'Vector kind'])
|
||||
df['tsne-2d-one'] = tsne_results[:, 0]
|
||||
|
|
@ -65,7 +65,7 @@ def plot_df(results, query: str) -> Optional[pd.DataFrame]:
|
|||
return None
|
||||
|
||||
|
||||
def main(method: str, file_path: str):
|
||||
def evaluate(method_name: str, file_path: str) -> tuple[float, float]:
|
||||
df = search_data.load_data()
|
||||
test_set = list(read_ground_truth(file_path, df))
|
||||
|
||||
|
|
@ -75,7 +75,7 @@ def main(method: str, file_path: str):
|
|||
dfs = []
|
||||
|
||||
for query, expected in tqdm.tqdm(test_set):
|
||||
search_results = search_data.search(query, method, df)
|
||||
search_results = search_data.search(query, method_name, df)
|
||||
|
||||
df_q = plot_df(search_results, query)
|
||||
if df_q is not None:
|
||||
|
|
@ -96,10 +96,13 @@ def main(method: str, file_path: str):
|
|||
if not os.path.isdir(OUT_DIR):
|
||||
os.makedirs(OUT_DIR)
|
||||
|
||||
output = "Precision: {0:.2f}%\nRecall: {0:.2f}%\n".format(precision_sum * 100 / len(test_set))
|
||||
precision = precision_sum * 100 / len(test_set)
|
||||
recall = recall_sum * 100 / len(test_set)
|
||||
|
||||
output = "Precision: {0:.2f}%\nRecall: {1:.2f}%\n".format(precision, recall)
|
||||
|
||||
print(output)
|
||||
with open(os.path.join(OUT_DIR, "{0}_prec_recall.txt".format(method)), "w") as f:
|
||||
with open(os.path.join(OUT_DIR, "{0}_prec_recall.txt".format(method_name)), "w") as f:
|
||||
f.write(output)
|
||||
|
||||
if len(dfs) > 0:
|
||||
|
|
@ -114,12 +117,33 @@ def main(method: str, file_path: str):
|
|||
legend="full",
|
||||
alpha=1.0
|
||||
)
|
||||
plt.savefig(os.path.join(OUT_DIR, "{0}_plot.png".format(method)))
|
||||
plt.savefig(os.path.join(OUT_DIR, "{0}_plot.png".format(method_name)))
|
||||
|
||||
return precision, recall
|
||||
|
||||
|
||||
def main():
|
||||
methods = ["tfidf", "freq", "lsi", "doc2vec"]
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("method", help="the method to compare similarities with", type=str, choices=methods + ["all"])
|
||||
parser.add_argument("ground_truth_file", help="file where ground truth comes from", type=str)
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.method == "all":
|
||||
df = pd.DataFrame(columns=["Engine", "Average Precision", "Average Recall"])
|
||||
|
||||
for i, method in enumerate(methods):
|
||||
print(f"Applying method {method}:")
|
||||
precision, recall = evaluate(method, args.ground_truth_file)
|
||||
df.loc[i, "Engine"] = method
|
||||
df.loc[i, "Average Precision"] = f"{precision:.2f}%"
|
||||
df.loc[i, "Average Recall"] = f"{recall:.2f}%"
|
||||
|
||||
print(df.to_markdown(index=False))
|
||||
else:
|
||||
evaluate(args.method, args.ground_truth_file)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("method", help="the method to compare similarities with", type=str)
|
||||
parser.add_argument("ground_truth_file", help="file where ground truth comes from", type=str)
|
||||
args = parser.parse_args()
|
||||
main(args.method, args.ground_truth_file)
|
||||
main()
|
||||
|
|
|
|||
110
report/main.tex
Normal file
110
report/main.tex
Normal file
|
|
@ -0,0 +1,110 @@
|
|||
%!TEX TS-program = pdflatexmk
|
||||
\documentclass{article}
|
||||
|
||||
\usepackage{algorithm}
|
||||
\usepackage{textcomp}
|
||||
\usepackage{xcolor}
|
||||
\usepackage{soul}
|
||||
\usepackage{booktabs}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\usepackage[T1]{fontenc}
|
||||
\usepackage{microtype}
|
||||
\usepackage{rotating}
|
||||
\usepackage{graphicx}
|
||||
\usepackage{paralist}
|
||||
\usepackage{tabularx}
|
||||
\usepackage{multicol}
|
||||
\usepackage{multirow}
|
||||
\usepackage{pbox}
|
||||
\usepackage{enumitem}
|
||||
\usepackage{colortbl}
|
||||
\usepackage{pifont}
|
||||
\usepackage{xspace}
|
||||
\usepackage{url}
|
||||
\usepackage{tikz}
|
||||
\usepackage{fontawesome}
|
||||
\usepackage{lscape}
|
||||
\usepackage{listings}
|
||||
\usepackage{color}
|
||||
\usepackage{anyfontsize}
|
||||
\usepackage{comment}
|
||||
\usepackage{soul}
|
||||
\usepackage{multibib}
|
||||
\usepackage{float}
|
||||
\usepackage{caption}
|
||||
\usepackage{subcaption}
|
||||
\usepackage{amssymb}
|
||||
\usepackage{amsmath}
|
||||
\usepackage{hyperref}
|
||||
|
||||
\title{Knowledge Management and Analysis \\ Project 01: Code Search}
|
||||
\author{Claudio Maggioni}
|
||||
\date{}
|
||||
|
||||
\begin{document}
|
||||
|
||||
\maketitle
|
||||
|
||||
\subsection*{Section 1 - Data Extraction}
|
||||
|
||||
The data extraction process scans through the files in the TensorFlow project to extract Python docstrings and symbol
|
||||
names for functions, classes and methods. A summary of the number of features extracted can be found in
|
||||
table~\ref{tab:count1}.
|
||||
|
||||
Report and comment figures about the extracted data (e.g., number of files; number of code
|
||||
entities of different kinds).
|
||||
|
||||
\begin{table}[H]
|
||||
\centering \scriptsize
|
||||
\begin{tabular}{cccc}
|
||||
\hline
|
||||
Type & Number \\
|
||||
\hline
|
||||
Python files & ? \\
|
||||
Classes & ? \\
|
||||
Functions & ? \\
|
||||
Methods & ? \\
|
||||
\hline
|
||||
\end{tabular}
|
||||
\caption{Count of created classes and properties.}
|
||||
\label{tab:count1}
|
||||
\end{table}
|
||||
|
||||
\subsection*{Section 2: Training of search engines}
|
||||
|
||||
Report and comment an example of a query and the results.
|
||||
|
||||
|
||||
\subsection*{Section 3: Evaluation of search engines}
|
||||
|
||||
Using the ground truth provided, evaluate and report recall and average precision for each of the four search engines; comment the differences among search engines.
|
||||
|
||||
|
||||
\begin{table} [H]
|
||||
\centering \scriptsize
|
||||
\begin{tabular}{cccc}
|
||||
\hline
|
||||
Engine & Avg Precision & Recall \\
|
||||
\hline
|
||||
Frequencies & ? & ? \\
|
||||
TD-IDF & ? & ? \\
|
||||
LSI & ? & ? \\
|
||||
Doc2Vec & ? & ? \\
|
||||
\hline
|
||||
\end{tabular}
|
||||
\caption{Evaluation of search engines.}
|
||||
\label{tab:tab2}
|
||||
\end{table}
|
||||
|
||||
\subsection*{Section 4: Visualisation of query results}
|
||||
|
||||
Include, comment and compare the t-SNE plots for LSI and for Doc2Vec.
|
||||
|
||||
\begin{figure}[H]
|
||||
\begin{center}
|
||||
\includegraphics[width=0.3\textwidth]{Figures/dummy_pic.png}
|
||||
\caption{Caption.}
|
||||
\label{fig:fig1}
|
||||
\end{center}
|
||||
\end{figure}
|
||||
\end{document}
|
||||
|
|
@ -2,7 +2,8 @@ coloredlogs==15.0.1
|
|||
gensim==4.3.2
|
||||
nltk==3.8.1
|
||||
numpy==1.26.1
|
||||
pandas==2.1.1
|
||||
pandas==2.1.2
|
||||
tqdm==4.66.1
|
||||
scikit-learn==1.3.2
|
||||
seaborn==0.13.0
|
||||
seaborn==0.13.0
|
||||
tabulate==0.9.0
|
||||
|
|
@ -3,6 +3,7 @@ import logging
|
|||
import os
|
||||
import re
|
||||
import typing
|
||||
from collections import defaultdict
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
|
|
@ -16,7 +17,7 @@ from gensim.models.doc2vec import TaggedDocument, Doc2Vec
|
|||
from gensim.similarities import SparseMatrixSimilarity
|
||||
from nltk.corpus import stopwords
|
||||
|
||||
nltk.download('stopwords')
|
||||
nltk.download('stopwords', quiet=True)
|
||||
|
||||
SCRIPT_DIR = os.path.abspath(os.path.dirname(__file__))
|
||||
IN_DATASET = os.path.join(SCRIPT_DIR, "data.csv")
|
||||
|
|
@ -24,32 +25,35 @@ DOC2VEC_MODEL = os.path.join(SCRIPT_DIR, "doc2vec_model.dat")
|
|||
|
||||
# using nltk stop words and example words for now
|
||||
STOP_WORDS = set(stopwords.words('english')) \
|
||||
.union(['test', 'tests', 'main', 'this', 'self'])
|
||||
.union(['test', 'tests', 'main', 'this', 'self', 'def', 'object', 'false', 'class', 'tuple', 'use', 'default',
|
||||
'none', 'dtype', 'true', 'function', 'returns', 'int', 'get', 'set', 'new', 'return', 'list', 'python',
|
||||
'numpy', 'type', 'name'])
|
||||
|
||||
|
||||
def find_all(regex, word):
|
||||
def find_all(regex: str, word: str, lower=True) -> list[str]:
|
||||
matches = re.finditer(regex, word)
|
||||
return [m.group(0).lower() for m in matches]
|
||||
return [m.group(0).lower() if lower else m.group(0) for m in matches]
|
||||
|
||||
|
||||
# https://stackoverflow.com/a/29920015
|
||||
def camel_case_split(word):
|
||||
def camel_case_split(word: str) -> list[str]:
|
||||
return find_all('.+?(?:(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])|$)', word)
|
||||
|
||||
|
||||
def identifier_split(identifier):
|
||||
def identifier_split(identifier: str) -> list[str]:
|
||||
return [y for x in identifier.split("_") for y in camel_case_split(x)]
|
||||
|
||||
|
||||
def comment_split(comment):
|
||||
return find_all('[A-Za-z0-9]+', comment)
|
||||
def comment_split(comment: str) -> list[str]:
|
||||
# Camel case split within "words" found takes care of referenced type names in the docstring comment
|
||||
return [s for word in find_all('[A-Za-z]+', comment, lower=False) for s in camel_case_split(word)]
|
||||
|
||||
|
||||
def remove_stopwords(input_bow_list):
|
||||
return [word for word in input_bow_list if word not in STOP_WORDS]
|
||||
def remove_stopwords(input_bow_list: list[str]) -> list[str]:
|
||||
return [word for word in input_bow_list if word not in STOP_WORDS and len(word) > 2]
|
||||
|
||||
|
||||
def get_bow(data, split_f):
|
||||
def get_bow(data: Optional[float | str], split_f) -> list[str]:
|
||||
if data is None or (type(data) == float and np.isnan(data)):
|
||||
return []
|
||||
return remove_stopwords(split_f(data))
|
||||
|
|
@ -83,17 +87,31 @@ def print_results(indexes_scores: list[tuple[int, float]], df):
|
|||
|
||||
def build_doc2vec_model(corpus_list):
|
||||
dvdocs = [TaggedDocument(text, [i]) for i, text in enumerate(corpus_list)]
|
||||
model = Doc2Vec(vector_size=100, epochs=100, sample=1e-5)
|
||||
model = Doc2Vec(vector_size=300, epochs=50, sample=0)
|
||||
model.build_vocab(dvdocs)
|
||||
model.train(dvdocs, total_examples=model.corpus_count, epochs=model.epochs)
|
||||
model.save(DOC2VEC_MODEL)
|
||||
return model
|
||||
|
||||
|
||||
def load_data() -> pd.DataFrame:
|
||||
def load_data(print_frequent=False) -> pd.DataFrame:
|
||||
df = pd.read_csv(IN_DATASET, index_col=0)
|
||||
df["name_bow"] = df["name"].apply(lambda n: get_bow(n, identifier_split))
|
||||
df["comment_bow"] = df["comment"].apply(lambda c: get_bow(c, comment_split))
|
||||
|
||||
if print_frequent:
|
||||
freq = defaultdict(int)
|
||||
for bow in df["name_bow"].tolist():
|
||||
for i in bow:
|
||||
freq[i] += 1
|
||||
|
||||
for bow in df["comment_bow"].tolist():
|
||||
for i in bow:
|
||||
freq[i] += 1
|
||||
|
||||
for key, value in sorted(freq.items(), key=lambda k: k[1], reverse=True)[:100]:
|
||||
print(f"{value}: {key}")
|
||||
|
||||
return df
|
||||
|
||||
|
||||
|
|
@ -164,17 +182,31 @@ def search(query: str, method: str, df: pd.DataFrame) -> SearchResults:
|
|||
|
||||
|
||||
def main():
|
||||
methods = ["tfidf", "freq", "lsi", "doc2vec"]
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("method", help="the method to compare similarities with", type=str)
|
||||
parser.add_argument("method", help="the method to compare similarities with", type=str,
|
||||
choices=methods + ["all"])
|
||||
parser.add_argument("query", help="the query to search the corpus with", type=str)
|
||||
parser.add_argument("-v", "--verbose", help="enable verbose logging", action='store_true')
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.verbose:
|
||||
coloredlogs.install()
|
||||
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
|
||||
|
||||
df = load_data()
|
||||
results = search(args.query, args.method, df)
|
||||
print_results(results.indexes_scores, df)
|
||||
|
||||
if args.method == "all":
|
||||
for method in methods:
|
||||
print(f"Applying method {method}:")
|
||||
results = search(args.query, method, df)
|
||||
print_results(results.indexes_scores, df)
|
||||
print()
|
||||
else:
|
||||
results = search(args.query, args.method, df)
|
||||
print_results(results.indexes_scores, df)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
coloredlogs.install()
|
||||
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
|
||||
main()
|
||||
|
|
|
|||
Loading…
Reference in a new issue