hw2: done
This commit is contained in:
parent
68b64da919
commit
c20fc288c2
17 changed files with 1941 additions and 0 deletions
as2_Maggioni_Claudio
142
as2_Maggioni_Claudio/README.md
Normal file
142
as2_Maggioni_Claudio/README.md
Normal file
|
|
@ -0,0 +1,142 @@
|
|||
# Assignment 2
|
||||
|
||||
In this assignment you are asked to:
|
||||
|
||||
1. Implement a neural network to classify images from the CIFAR10 dataset;
|
||||
2. Fine-tune a pre-trained neural network to classify rock, paper, scissors hand gestures.
|
||||
|
||||
Both requests are very similar to what we have seen during the labs. However, you are required to follow **exactly** the assignment's specifications.
|
||||
|
||||
Once completed, please submit your solution on the iCorsi platform following the instructions below.
|
||||
|
||||
|
||||
## Tasks
|
||||
|
||||
|
||||
### T1. Follow our recipe
|
||||
|
||||
Implement a multi-class classifier to identify the subject of the images from [CIFAR-10](https://www.cs.toronto.edu/%7Ekriz/cifar.html) data set. To simply the problem, we restrict the classes to 3: `airplane`, `automobile` and `bird`.
|
||||
|
||||
1. Download and load CIFAR-10 dataset using the following [function](https://www.tensorflow.org/api_docs/python/tf/keras/datasets/cifar10/load_data), and consider only the first three classes. Check `src/utils.py`, there is already a function for this!
|
||||
2. Preprocess the data:
|
||||
- Normalize each pixel of each channel so that the range is [0, 1];
|
||||
- Create one-hot encoding of the labels.
|
||||
3. Build a neural network with the following architecture:
|
||||
- Convolutional layer, with 8 filters of size 5 by 5, stride of 1 by 1, and ReLU activation;
|
||||
- Max pooling layer, with pooling size of 2 by 2;
|
||||
- Convolutional layer, with 16 filters of size 3 by 3, stride of 2 by 2, and ReLU activation;
|
||||
- Average pooling layer, with pooling size of 2 by 2;
|
||||
- Layer to convert the 2D feature maps to vectors (Flatten layer);
|
||||
- Dense layer with 8 neurons and tanh activation;
|
||||
- Dense output layer with softmax activation;
|
||||
4. Train the model on the training set from point 1 for 500 epochs:
|
||||
- Use the RMSprop optimization algorithm, with a learning rate of 0.003 and a batch size of 128;
|
||||
- Use categorical cross-entropy as a loss function;
|
||||
- Implement early stopping, monitoring the validation accuracy of the model with a patience of 10 epochs and use 20% of the training data as validation set;
|
||||
- When early stopping kicks in, and the training procedure stops, restore the best model found during training.
|
||||
5. Draw a plot with epochs on the x-axis and with two graphs: the train accuracy and the validation accuracy (remember to add a legend to distinguish the two graphs!).
|
||||
6. Assess the performances of the network on the test set loaded in point 1, and provide an estimate of the classification accuracy that you expect on new and unseen images.
|
||||
7. **Bonus** (Optional) Tune the learning rate and the number of neurons in the last dense hidden layer with a **grid search** to improve the performances (if feasible).
|
||||
- Consider the following options for the two hyper-parameters (4 models in total):
|
||||
+ learning rate: [0.01, 0.0001]
|
||||
+ number of neurons: [16, 64]
|
||||
- Keep all the other hyper-parameters as in point 3.
|
||||
- Perform a grid search on the chosen ranges based on hold-out cross-validation in the training set and identify the most promising hyper-parameter setup.
|
||||
- Compare the accuracy on the test set achieved by the most promising configuration with that of the model obtained in point 4. Are the accuracy levels statistically different?
|
||||
|
||||
|
||||
### T2. Transfer learning
|
||||
|
||||
In this task, we will fine-tune the last layer of a pretrained model in order to build a classifier for the rock, paper, scissors dataset that we acquired for the lab. The objective is to make use of the experience collected on a task to bootstrap the performances on a different task. We are going to use the VGG16 network, pretrained on Imagenet to compete in the ILSVRC-2014 competition.
|
||||
|
||||
VGG16 is very expensive to train from scratch, but luckily the VGG team publicly released the trained weights of the network, so that people could use it for transfer learning. As we discussed during classes, this can be achieved by removing the last fully connected layers form the pretrained model and by using the output of the convolutional layers (with freezed weights) as input to a new fully connected network. This last part of the model is then trained from scratch on the task of interest.
|
||||
|
||||
1. Use `keras` to download a pretrained version of the `vgg16` network. You can start from this snippet of code:
|
||||
|
||||
```python
|
||||
from tensorflow.keras import applications
|
||||
|
||||
# since VGG16 was trained on high-resolution images using a low resolution might not be a good idea
|
||||
img_h, img_w = 224, 224
|
||||
|
||||
# Build the VGG16 network and download pre-trained weights and remove the last dense layers.
|
||||
vgg16 = applications.VGG16(weights='imagenet',
|
||||
include_top=False,
|
||||
input_shape=(img_h, img_w, 3))
|
||||
# Freezes the network weights
|
||||
vgg16.trainable = False
|
||||
|
||||
# Now you can use vgg16 as you would use any other layer.
|
||||
# Example:
|
||||
|
||||
net = Sequential()
|
||||
net.add(vgg16)
|
||||
net.add(Flatten())
|
||||
net.add(Dense(...))
|
||||
...
|
||||
```
|
||||
2. Download and preprocess the rock, paper, scissor dataset that we collected for the lab.
|
||||
- You find the functions to download and build the dataset in `src/utils.py`.
|
||||
- Vgg16 provides a function to prepropress the input (`applications.vgg16.preprocess_input`). You may decide to use it.
|
||||
- Use 224x224 as image dimension.
|
||||
4. Add a hidden layer (use any number of units and the activation function that you want), then add an output layer suitable for the hand gesture classification problem.
|
||||
6. Train with and without data augmentation and report the learning curves (train and validation accuracy) for both cases.
|
||||
- Turn on the GPU environment on Colab, otherwise training will be slow.
|
||||
- Train for 50 epochs or until convergence.
|
||||
- Comment if using data augmentation led to an improvement or not.
|
||||
|
||||
|
||||
## Instructions
|
||||
|
||||
### Tools
|
||||
|
||||
Your solution must be entirely coded in **Python 3** ([not Python 2](https://python3statement.org/)).
|
||||
We recommend to use Keras from TensorFlow2 that we seen in the labs, so that you can reuse the code in there as reference.
|
||||
|
||||
All the required tasks can be completed using Keras. On the [documentation page](https://www.tensorflow.org/api_docs/python/tf/keras/) there is a useful search field that allows you to smoothly find what you are looking for.
|
||||
You can develop your code in Colab, where you have access to a GPU, or you can install the libraries on your machine and develop locally.
|
||||
|
||||
|
||||
### Submission
|
||||
|
||||
In order to complete the assignment, you must submit a zip file named `as2_surname_name.zip` on the iCorsi platform containing:
|
||||
|
||||
1. A report in `.pdf` format containing the plots and comments of the two tasks. You can use the `.tex` source code provided in the repo (not mandatory).
|
||||
2. The two best models you find for both the tasks (one per task). By default, the keras function to save the model outputs a folder with several files inside. If you prefer a more compact solution, just append `.h5` at the end of the name you use to save the model to end up with a single file.
|
||||
3. A working example `run_task1.py` that loads the test set in CIFAR-10 dataset, preprocesses the data, loads the trained model from file and evaluate the accuracy. In case you completed the bonus point, turn in the model with the highest accuracy.
|
||||
3. A working example `run_task2.py` that loads the test set of the rock, paper, scissors dataset, preprocesses the data, loads the trained model from file and evaluate the accuracy.
|
||||
4. A folder `src` with all the source code you used to build, train, and evaluate your models.
|
||||
|
||||
The zip file should eventually looks like as follows
|
||||
|
||||
```
|
||||
as2_surname_name/
|
||||
report_surname_name.pdf
|
||||
deliverable/
|
||||
run_task1.py
|
||||
run_task2.py
|
||||
nn_task1/ # or any other file storing the model from task T1, e.g., nn_task1.h5
|
||||
nn_task2/ # or any other file storing the model from task T2, e.g., nn_task2.h5
|
||||
src/
|
||||
file1.py
|
||||
file2.py
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
### Evaluation criteria
|
||||
|
||||
You will get a positive evaluation if:
|
||||
|
||||
- your code runs out of the box (i.e., without needing to change your code to evaluate the assignment);
|
||||
- your code is properly commented;
|
||||
- the performance assessment is conducted appropriately;
|
||||
|
||||
You will get a negative evaluation if:
|
||||
|
||||
- we realize that you copied your solution;
|
||||
- your code requires us to edit things manually in order to work;
|
||||
- you did not follow our detailed instructions in tasks T1 and T2.
|
||||
|
||||
Bonus parts are optional and are not required to achieve the maximum grade, however they can grant you extra points.
|
||||
|
||||
BIN
as2_Maggioni_Claudio/deliverable/nn_task1/nn_task1.h5
(Stored with Git LFS)
Normal file
BIN
as2_Maggioni_Claudio/deliverable/nn_task1/nn_task1.h5
(Stored with Git LFS)
Normal file
Binary file not shown.
BIN
as2_Maggioni_Claudio/deliverable/nn_task2/nn_task2_aug.h5
(Stored with Git LFS)
Normal file
BIN
as2_Maggioni_Claudio/deliverable/nn_task2/nn_task2_aug.h5
(Stored with Git LFS)
Normal file
Binary file not shown.
BIN
as2_Maggioni_Claudio/deliverable/nn_task2/nn_task2_noaug.h5
(Stored with Git LFS)
Normal file
BIN
as2_Maggioni_Claudio/deliverable/nn_task2/nn_task2_noaug.h5
(Stored with Git LFS)
Normal file
Binary file not shown.
59
as2_Maggioni_Claudio/deliverable/run_task1.py
Normal file
59
as2_Maggioni_Claudio/deliverable/run_task1.py
Normal file
|
|
@ -0,0 +1,59 @@
|
|||
from tensorflow.keras.models import load_model
|
||||
import os
|
||||
import pickle
|
||||
import urllib.request as http
|
||||
from zipfile import ZipFile
|
||||
from tensorflow.keras import utils
|
||||
|
||||
import tensorflow as tf
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
from tensorflow.keras import layers as keras_layers
|
||||
from tensorflow.keras import backend as K
|
||||
from tensorflow.keras.datasets import cifar10
|
||||
from tensorflow.keras.models import save_model, load_model
|
||||
|
||||
|
||||
def load_cifar10(num_classes=3):
|
||||
"""
|
||||
Downloads CIFAR-10 dataset, which already contains a training and test set,
|
||||
and return the first `num_classes` classes.
|
||||
Example of usage:
|
||||
|
||||
>>> (x_train, y_train), (x_test, y_test) = load_cifar10()
|
||||
|
||||
:param num_classes: int, default is 3 as required by the assignment.
|
||||
:return: the filtered data.
|
||||
"""
|
||||
(x_train_all, y_train_all), (x_test_all, y_test_all) = cifar10.load_data()
|
||||
|
||||
fil_train = tf.where(y_train_all[:, 0] < num_classes)[:, 0]
|
||||
fil_test = tf.where(y_test_all[:, 0] < num_classes)[:, 0]
|
||||
|
||||
y_train = y_train_all[fil_train]
|
||||
y_test = y_test_all[fil_test]
|
||||
|
||||
x_train = x_train_all[fil_train]
|
||||
x_test = x_test_all[fil_test]
|
||||
|
||||
return (x_train, y_train), (x_test, y_test)
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
_, (x_test, y_test) = load_cifar10()
|
||||
|
||||
# Load the trained models
|
||||
model_task1 = load_model('nn_task1/nn_task1.h5')
|
||||
x_test_n = x_test / 255
|
||||
y_test_n = utils.to_categorical(y_test, 3)
|
||||
|
||||
# Predict on the given samples
|
||||
#for example
|
||||
y_pred_task1 = model_task1.predict(x_test_n)
|
||||
|
||||
# Evaluate the missclassification error on the test set
|
||||
# for example
|
||||
assert y_test_n.shape == y_pred_task1.shape
|
||||
test_loss, test_accuracy = model_task1.evaluate(x_test_n, y_test_n) # evaluate accuracy with proper function
|
||||
print("Accuracy model task 1:", test_accuracy)
|
||||
122
as2_Maggioni_Claudio/deliverable/run_task2.py
Normal file
122
as2_Maggioni_Claudio/deliverable/run_task2.py
Normal file
|
|
@ -0,0 +1,122 @@
|
|||
import os
|
||||
import pickle
|
||||
import urllib.request as http
|
||||
from zipfile import ZipFile
|
||||
from tensorflow.keras import Sequential, applications
|
||||
|
||||
import tensorflow as tf
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
from tensorflow.keras import utils
|
||||
|
||||
from tensorflow.keras import layers as keras_layers
|
||||
from tensorflow.keras import backend as K
|
||||
from tensorflow.keras.datasets import cifar10
|
||||
from tensorflow.keras.models import save_model, load_model
|
||||
|
||||
import torch
|
||||
from keras.preprocessing.image import img_to_array, array_to_img
|
||||
|
||||
def load_keras_model(filename):
|
||||
"""
|
||||
Loads a compiled Keras model saved with models.save_model.
|
||||
|
||||
:param filename: string, path to the file storing the model.
|
||||
:return: the model.
|
||||
"""
|
||||
model = load_model(filename)
|
||||
return model
|
||||
|
||||
def load_rps(download=False, path='rps', reduction_factor=1):
|
||||
"""
|
||||
Downloads the rps dataset and returns the training and test sets.
|
||||
Example of usage:
|
||||
|
||||
>>> (x_train, y_train), (x_test, y_test) = load_rps()
|
||||
|
||||
:param download: bool, default is False but for the first call should be True.
|
||||
:param path: str, subdirectory in which the images should be downloaded, default is 'rps'.
|
||||
:param reduction_factor: int, factor of reduction of the dataset (len = old_len // reduction_factor).
|
||||
:return: the images and labels split into training and validation sets.
|
||||
"""
|
||||
url = 'https://drive.switch.ch/index.php/s/xjXhuYDUzoZvL02/download'
|
||||
classes = ('rock', 'paper', 'scissors')
|
||||
rps_dir = os.path.abspath(path)
|
||||
filename = os.path.join(rps_dir, 'data.zip')
|
||||
if not os.path.exists(rps_dir) and not download:
|
||||
raise ValueError("Dataset not in the path. You should call this function with `download=True` the first time.")
|
||||
if download:
|
||||
os.makedirs(rps_dir, exist_ok=True)
|
||||
print(f"Downloading rps images in {rps_dir} (may take a couple of minutes)")
|
||||
path, msg = http.urlretrieve(url, filename)
|
||||
with ZipFile(path, 'r') as zip_ref:
|
||||
zip_ref.extractall(rps_dir)
|
||||
os.remove(filename)
|
||||
train_dir, test_dir = os.path.join(rps_dir, 'train'), os.path.join(rps_dir, 'test')
|
||||
print("Loading training set...")
|
||||
x_train, y_train = load_images_with_label(train_dir, classes)
|
||||
x_train, y_train = x_train[::reduction_factor], y_train[::reduction_factor]
|
||||
print("Loaded %d images for training" % len(y_train))
|
||||
print("Loading test set...")
|
||||
x_test, y_test = load_images_with_label(test_dir, classes)
|
||||
x_test, y_test = x_test[::reduction_factor], y_test[::reduction_factor]
|
||||
print("Loaded %d images for testing" % len(y_test))
|
||||
return (x_train, y_train), (x_test, y_test)
|
||||
|
||||
def load_images(path):
|
||||
img_files = os.listdir(path)
|
||||
imgs, labels = [], []
|
||||
for i in img_files:
|
||||
if i.endswith('.jpg'):
|
||||
# load the image (here you might want to resize the img to save memory)
|
||||
imgs.append(Image.open(os.path.join(path, i)).copy())
|
||||
return imgs
|
||||
|
||||
def load_images_with_label(path, classes):
|
||||
imgs, labels = [], []
|
||||
for c in classes:
|
||||
# iterate over all the files in the folder
|
||||
c_imgs = load_images(os.path.join(path, c))
|
||||
imgs.extend(c_imgs)
|
||||
labels.extend([c] * len(c_imgs))
|
||||
return imgs, labels
|
||||
|
||||
if __name__ == '__main__':
|
||||
model_aug = load_keras_model("nn_task2/nn_task2_aug.h5")
|
||||
model_noaug = load_keras_model("nn_task2/nn_task2_noaug.h5")
|
||||
|
||||
# Resize the input images
|
||||
resize = lambda x: [e.resize((224,224)) for e in x]
|
||||
|
||||
def process(x):
|
||||
x_n = resize(x)
|
||||
for i in range(len(x)):
|
||||
bgr = img_to_array(x_n[i])[..., ::-1]
|
||||
mean = [103.939, 116.779, 123.68]
|
||||
bgr -= mean
|
||||
x_n[i] = bgr
|
||||
return x_n
|
||||
|
||||
_, (x_test, y_test) = load_rps(download=not os.path.exists("rps"))
|
||||
x_test_n = tf.convert_to_tensor(process(x_test))
|
||||
|
||||
MAP = {'scissors': 0, 'paper': 1, 'rock': 2}
|
||||
print(MAP)
|
||||
mapfunc = np.vectorize(lambda x: MAP[x])
|
||||
y_test_n = utils.to_categorical(mapfunc(y_test), 3)
|
||||
|
||||
print(np.shape(y_test_n))
|
||||
|
||||
y_pred_task1 = model_noaug.predict(x_test_n)
|
||||
y_pred_task2 = model_aug.predict(x_test_n)
|
||||
|
||||
# Evaluate the missclassification error on the test set
|
||||
# for example
|
||||
assert y_test_n.shape == y_pred_task1.shape
|
||||
acc = model_noaug.evaluate(x_test_n, y_test_n)[1] # evaluate accuracy with proper function
|
||||
print("Accuracy model task 2 (no augmentation):", acc)
|
||||
|
||||
assert y_test_n.shape == y_pred_task2.shape
|
||||
acc = model_aug.evaluate(x_test_n, y_test_n)[1] # evaluate accuracy with proper function
|
||||
print("Accuracy model task 2 (with augmentation):", acc)
|
||||
BIN
as2_Maggioni_Claudio/report_Maggioni_Claudio.pdf
Normal file
BIN
as2_Maggioni_Claudio/report_Maggioni_Claudio.pdf
Normal file
Binary file not shown.
236
as2_Maggioni_Claudio/report_Maggioni_Claudio.tex
Normal file
236
as2_Maggioni_Claudio/report_Maggioni_Claudio.tex
Normal file
|
|
@ -0,0 +1,236 @@
|
|||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% Machine Learning Assignment Template
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\documentclass[11pt]{scrartcl}
|
||||
\newcommand*\student[1]{\newcommand{\thestudent}{{#1}}}
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% INSERT HERE YOUR NAME
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\student{Claudio Maggioni}
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% PACKAGES AND OTHER DOCUMENT CONFIGURATIONS
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\usepackage[utf8]{inputenc} % Required for inputting international characters
|
||||
\usepackage[T1]{fontenc} % Use 8-bit encoding
|
||||
\usepackage[sc]{mathpazo}
|
||||
\usepackage{caption, subcaption}
|
||||
\usepackage[colorlinks=true]{hyperref}
|
||||
\usepackage{inconsolata}
|
||||
|
||||
\usepackage[english]{babel} % English language hyphenation
|
||||
\usepackage{amsmath, amsfonts} % Math packages
|
||||
\usepackage{listings} % Code listings, with syntax highlighting
|
||||
\usepackage{graphicx} % Required for inserting images
|
||||
\graphicspath{{Figures/}{./}} % Specifies where to look for included images (trailing slash required)
|
||||
\usepackage{float}
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% DOCUMENT MARGINS
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\usepackage{geometry} % For page dimensions and margins
|
||||
\geometry{
|
||||
paper=a4paper,
|
||||
top=2.5cm, % Top margin
|
||||
bottom=3cm, % Bottom margin
|
||||
left=3cm, % Left margin
|
||||
right=3cm, % Right margin
|
||||
}
|
||||
\setlength\parindent{0pt}
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% SECTION TITLES
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\usepackage{sectsty}
|
||||
\sectionfont{\vspace{6pt}\centering\normalfont\scshape}
|
||||
\subsectionfont{\normalfont\bfseries} % \subsection{} styling
|
||||
\subsubsectionfont{\normalfont\itshape} % \subsubsection{} styling
|
||||
\paragraphfont{\normalfont\scshape} % \paragraph{} styling
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% HEADERS AND FOOTERS
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\usepackage{scrlayer-scrpage}
|
||||
\ofoot*{\pagemark} % Right footer
|
||||
\ifoot*{\thestudent} % Left footer
|
||||
\cfoot*{} % Centre footer
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% TITLE SECTION
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\title{
|
||||
\normalfont\normalsize
|
||||
\textsc{Machine Learning\\%
|
||||
Universit\`a della Svizzera italiana}\\
|
||||
\vspace{25pt}
|
||||
\rule{\linewidth}{0.5pt}\\
|
||||
\vspace{20pt}
|
||||
{\huge Assignment 2}\\
|
||||
\vspace{12pt}
|
||||
\rule{\linewidth}{1pt}\\
|
||||
\vspace{12pt}
|
||||
}
|
||||
|
||||
\author{\LARGE \thestudent}
|
||||
|
||||
\date{\normalsize\today}
|
||||
|
||||
\begin{document}
|
||||
|
||||
\maketitle
|
||||
|
||||
In this assignment you are asked to:
|
||||
|
||||
\begin{enumerate}
|
||||
\item Implement a neural network to classify images from the \texttt{CIFAR10} dataset;
|
||||
\item Fine-tune a pre-trained neural network to classify rock, paper, scissors hand gestures.
|
||||
\end{enumerate}
|
||||
|
||||
Both requests are very similar to what we have seen during the labs. However, you are required to follow \textbf{exactly} the assignment's specifications.
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% Task 1
|
||||
%----------------------------------------------------------------------------------------
|
||||
|
||||
\section{Follow our recipe}
|
||||
|
||||
Implement a multi-class classifier to identify the subject of the images from \href{https://www.cs.toronto.edu/\%7Ekriz/cifar.html}{\texttt{CIFAR-10}} data set. To simply the problem, we restrict the classes to 3: \texttt{airplane}, \texttt{automobile} and \texttt{bird}.
|
||||
|
||||
\begin{enumerate}
|
||||
\item Download and load \texttt{CIFAR-10} dataset using the following \href{https://www.tensorflow.org/api_docs/python/tf/keras/datasets/cifar10/load_data}{function}, and consider only the first three classes. Check \texttt{src/utils.py}, there is already a function for this!
|
||||
\item Preprocess the data:
|
||||
\begin{itemize}
|
||||
\item Normalize each pixel of each channel so that the range is [0, 1];
|
||||
\item Create one-hot encoding of the labels.
|
||||
\end{itemize}
|
||||
\item Build a neural network with the following architecture:
|
||||
\begin{itemize}
|
||||
\item Convolutional layer, with 8 filters of size 5$\times$5, stride of 1$\times$1, and ReLU activation;
|
||||
\item Max pooling layer, with pooling size of 2$\times$2;
|
||||
\item Convolutional layer, with 16 filters of size 3$\times$3, stride of 2$\times$2, and ReLU activation;
|
||||
\item Average pooling layer, with pooling size of 2$\times$2;
|
||||
\item Layer to convert the 2D feature maps to vectors (Flatten layer);
|
||||
\item Dense layer with 8 neurons and tanh activation;
|
||||
\item Dense output layer with softmax activation;
|
||||
\end{itemize}
|
||||
\item Train the model on the training set from point 1 for 500 epochs:
|
||||
\begin{itemize}
|
||||
\item Use the RMSprop optimization algorithm, with a learning rate of 0.003 and a batch size of 128;
|
||||
\item Use categorical cross-entropy as a loss function;
|
||||
\item Implement early stopping, monitoring the validation accuracy of the model with a patience of 10 epochs and use 20\% of the training data as validation set;
|
||||
\item When early stopping kicks in, and the training procedure stops, restore the best model found during training.
|
||||
\end{itemize}
|
||||
\item Draw a plot with epochs on the $x$-axis and with two graphs: the train accuracy and the validation accuracy (remember to add a legend to distinguish the two graphs!).
|
||||
\item Assess the performances of the network on the test set loaded in point 1, and provide an estimate of the classification accuracy that you expect on new and unseen images.
|
||||
\item \textbf{Bonus} (Optional) Tune the learning rate and the number of neurons in the last dense hidden layer with a \textbf{grid search} to improve the performances (if feasible).
|
||||
\begin{itemize}
|
||||
\item Consider the following options for the two hyper-parameters (4 models in total):
|
||||
\begin{itemize}
|
||||
\item learning rate: [0.01, 0.0001]
|
||||
\item number of neurons: [16, 64]
|
||||
\end{itemize}
|
||||
\item Keep all the other hyper-parameters as in point 3.
|
||||
\item Perform a grid search on the chosen ranges based on hold-out cross-validation in the training set and identify the most promising hyper-parameter setup.
|
||||
\item Compare the accuracy on the test set achieved by the most promising configuration with that of the model obtained in point 4. Are the accuracy levels statistically different?
|
||||
\end{itemize}
|
||||
\end{enumerate}
|
||||
|
||||
\subsection{Comment}
|
||||
|
||||
The network model was built and trained according to the given specification.
|
||||
|
||||
The performance on the given test set is of $0.3649$ loss and $86.4\%$ accuracy. In order to assess performance on new and unseen images
|
||||
a statistical confidence interval is necessary. Since the accuracy is by construction a binomial measure (since an image can either be correctly
|
||||
classified or not, and we repeat this Bernoulli process for each test set datapoint), we perform a binomial distribution confidence interval computation
|
||||
for 95\% confidence. The code use to do this is found in the notebook \texttt{src/Assignment 2.ipynb} under the section \textit{Statistical tests on CIFAR classifier}.
|
||||
We conclude stating that with 95\% confidence the accuracy for new and unseen images will fall between $\approx 85.12\%$ and $\approx 87.59\%$.
|
||||
|
||||
The training and validation accuracy curves for the network is shown below:
|
||||
|
||||
\begin{figure}[H]
|
||||
\centering
|
||||
\resizebox{\textwidth}{!}{%
|
||||
\includegraphics{./t1_plot.png}}
|
||||
\caption{Training and validation accuracy curves during fitting for the CIFAR10 classifier}
|
||||
\end{figure}
|
||||
|
||||
%----------------------------------------------------------------------------------------
|
||||
% Task 2
|
||||
%----------------------------------------------------------------------------------------
|
||||
\newpage
|
||||
\section{Transfer learning}
|
||||
|
||||
In this task, we will fine-tune the last layer of a pretrained model in order to build a classifier for the \emph{rock, paper, scissors dataset} that we acquired for the lab. The objective is to make use of the experience collected on a task to bootstrap the performances on a different task. We are going to use the \texttt{VGG16} network, pretrained on Imagenet to compete in the ILSVRC-2014 competition.\\
|
||||
|
||||
\texttt{VGG16} is very expensive to train from scratch, but luckily the VGG team publicly released the trained weights of the network, so that people could use it for transfer learning. As we discussed during classes, this can be achieved by \textbf{removing the last fully connected layers} form the pretrained model and by using the output of the convolutional layers (with freezed weights) as input to a \textbf{new fully connected network}. This last part of the model is then trained from scratch on the task of interest.
|
||||
|
||||
\begin{enumerate}
|
||||
\item Use \texttt{keras} to download a pretrained version of the \texttt{vgg16} network. You can start from the snippet of code you find on the \href{https://github.com/marshka/ml-20-21/tree/main/assignment\_2}{repository} of the assignment.
|
||||
\item Download and preprocess the rock, paper, scissor dataset that we collected for the lab. You find the functions to download and build the dataset in \texttt{src/utils.py}. Vgg16 provides a function to prepropress the input\\
|
||||
\texttt{applications.vgg16.preprocess\_input}\\
|
||||
You may decide to use it.
|
||||
Use $224 \times 224$ as image dimension.
|
||||
\item Add a hidden layer (use any number of units and the activation function that you want), then add an output layer suitable for the hand gesture classification problem.
|
||||
\item Train with and without \textbf{data augmentation} and report the learning curves (train and validation accuracy) for both cases.
|
||||
\begin{itemize}
|
||||
\item Turn on the GPU environment on Colab, otherwise training will be slow.
|
||||
\item Train for 50 epochs or until convergence.
|
||||
\item Comment if using data augmentation led to an improvement or not.
|
||||
\end{itemize}
|
||||
\end{enumerate}
|
||||
|
||||
\subsection{Comment}
|
||||
|
||||
The built network in its dense part is composed by a 128-neuron ReLU-activated hidden layer and a 3-neuron softmax output layer.
|
||||
The input to the network is at first resized to 224x224 size and then normalized according to VGG16 normalization factors
|
||||
(refer to the function \texttt{process\_vgg16} in the \texttt{src/Assignment 2.ipynb} notebook for details on the normalization process).
|
||||
Classification labels were first converted from string labels to numeric ones, (i.e. \texttt{'scissors'} = 0,
|
||||
\texttt{'paper'} = 1, \texttt{'rock'} = 2), and then the numeric encoding was in turn converted to a one-hot encoding using the
|
||||
\texttt{keras.utils.to\_categorical} function.
|
||||
|
||||
Both the data-augmented and non-augmented network were trained using the ADAM optimizer with $0.001$ learning rate for 50 epochs with
|
||||
an early stopping procedure with 10 epochs patience.
|
||||
|
||||
Both models were saved and both can be run at the same time on the given test set by executing \texttt{deliverable/run\_task2.py}.
|
||||
|
||||
The training and validation accuracy curves for both the data-augmented and the not augmented networks are shown below:
|
||||
|
||||
\begin{figure}[H]
|
||||
\centering
|
||||
\resizebox{\textwidth}{!}{%
|
||||
\includegraphics{./t2_noaug.png}}
|
||||
\caption{Training and validation accuracy curves during fitting for the not data augmented VGG16 classifier}
|
||||
\end{figure}
|
||||
|
||||
\begin{figure}[H]
|
||||
\centering
|
||||
\resizebox{\textwidth}{!}{%
|
||||
\includegraphics{./t2_aug.png}}
|
||||
\caption{Training and validation accuracy curves during fitting for the data augmented VGG16 classifier}
|
||||
\end{figure}
|
||||
|
||||
\subsection{T-Test}
|
||||
|
||||
The findings shown below were computed using the script \texttt{src/t\_test.py}.
|
||||
|
||||
To compare the trained model with and without data augmentation, we perform a two-tailed Student T-test between the models.
|
||||
The test report that the models have different accuracy with $99.999973\%$ confidence, and the model trained with data augmentation
|
||||
has lower variance. Therefore, we conclude that the model trained with data augmentation is the statistically better model out of the two.
|
||||
|
||||
The student T-test of course is a valid argument only for this specific instance of the application of data augmentation. However,
|
||||
in the general case we can say that performing data augmentation on the training and validation data is intuitively better in order to
|
||||
assure the network is able to correctly identify rock, paper or scissors from all angles and zoom levels.
|
||||
|
||||
On the given test set, the model trained with data augmentation has $\approx 90.00\%$ accuracy while the model trained without data augmentation
|
||||
has $\approx 77.33\%$ accuracy.
|
||||
|
||||
\end{document}
|
||||
1251
as2_Maggioni_Claudio/src/Assignment 2.ipynb
Normal file
1251
as2_Maggioni_Claudio/src/Assignment 2.ipynb
Normal file
File diff suppressed because one or more lines are too long
BIN
as2_Maggioni_Claudio/src/Assignment 2.pdf
Normal file
BIN
as2_Maggioni_Claudio/src/Assignment 2.pdf
Normal file
Binary file not shown.
65
as2_Maggioni_Claudio/src/my_civar10.csv
Normal file
65
as2_Maggioni_Claudio/src/my_civar10.csv
Normal file
|
|
@ -0,0 +1,65 @@
|
|||
epoch,accuracy,loss,val_accuracy,val_loss
|
||||
0,0.5835000276565552,0.9027522206306458,0.6930000185966492,0.7313074469566345
|
||||
1,0.6981666684150696,0.7197360992431641,0.7573333382606506,0.6185170412063599
|
||||
2,0.7268333435058594,0.649580717086792,0.7166666388511658,0.6847538352012634
|
||||
3,0.7490000128746033,0.6051502823829651,0.6726666688919067,0.8005362749099731
|
||||
4,0.7670000195503235,0.5711988806724548,0.7213333249092102,0.6812124252319336
|
||||
5,0.7771666646003723,0.5591645836830139,0.7956666946411133,0.5224239230155945
|
||||
6,0.7922499775886536,0.5163288712501526,0.7746666669845581,0.560214638710022
|
||||
7,0.796750009059906,0.5033565163612366,0.7696666717529297,0.5671213269233704
|
||||
8,0.8021666407585144,0.4886069595813751,0.7850000262260437,0.5377761721611023
|
||||
9,0.8159166574478149,0.46416983008384705,0.7973333597183228,0.5045124292373657
|
||||
10,0.8112499713897705,0.4600376784801483,0.7876666784286499,0.5360596776008606
|
||||
11,0.8222500085830688,0.44709986448287964,0.8173333406448364,0.46527454257011414
|
||||
12,0.8263333439826965,0.4383203983306885,0.8193333148956299,0.4525858163833618
|
||||
13,0.8272500038146973,0.42477884888648987,0.8209999799728394,0.46459323167800903
|
||||
14,0.828166663646698,0.4239223301410675,0.8133333325386047,0.4657036066055298
|
||||
15,0.8364999890327454,0.4106995165348053,0.8316666483879089,0.43970581889152527
|
||||
16,0.8379999995231628,0.40464073419570923,0.8309999704360962,0.43921899795532227
|
||||
17,0.843500018119812,0.3954917788505554,0.7919999957084656,0.5195531845092773
|
||||
18,0.8410833477973938,0.3955632746219635,0.8273333311080933,0.43989425897598267
|
||||
19,0.8451666831970215,0.3902503252029419,0.8213333487510681,0.4508914649486542
|
||||
20,0.8479999899864197,0.38045644760131836,0.8373333215713501,0.4345586895942688
|
||||
21,0.8519166707992554,0.3750855624675751,0.8363333344459534,0.42357707023620605
|
||||
22,0.8511666655540466,0.3793516457080841,0.8386666774749756,0.4240257143974304
|
||||
23,0.8541666865348816,0.36603105068206787,0.8256666660308838,0.44586217403411865
|
||||
24,0.8585000038146973,0.36231645941734314,0.8309999704360962,0.445521742105484
|
||||
25,0.856166660785675,0.36122143268585205,0.8373333215713501,0.4368632435798645
|
||||
26,0.8581666946411133,0.35858675837516785,0.8403333425521851,0.4214838743209839
|
||||
27,0.859250009059906,0.3539867699146271,0.8429999947547913,0.427225261926651
|
||||
28,0.8620833158493042,0.35064488649368286,0.8456666469573975,0.4140232801437378
|
||||
29,0.8643333315849304,0.34821170568466187,0.8349999785423279,0.41891446709632874
|
||||
30,0.8681666851043701,0.3375576138496399,0.8396666646003723,0.4178491234779358
|
||||
31,0.8667500019073486,0.3405560851097107,0.8173333406448364,0.4889259934425354
|
||||
32,0.8673333525657654,0.3408810496330261,0.8376666903495789,0.4319263994693756
|
||||
33,0.8669999837875366,0.3369854688644409,0.843999981880188,0.4151623845100403
|
||||
34,0.8674166798591614,0.333772212266922,0.8483333587646484,0.4048003852367401
|
||||
35,0.8738333582878113,0.3248937129974365,0.8296666741371155,0.44129908084869385
|
||||
36,0.8731666803359985,0.32493579387664795,0.8226666450500488,0.4935603141784668
|
||||
37,0.8696666955947876,0.3261963427066803,0.8453333377838135,0.41957756876945496
|
||||
38,0.8737499713897705,0.32006925344467163,0.8403333425521851,0.4206053912639618
|
||||
39,0.874750018119812,0.31747952103614807,0.8383333086967468,0.44560351967811584
|
||||
40,0.8740000128746033,0.31876373291015625,0.8349999785423279,0.42805150151252747
|
||||
41,0.878250002861023,0.3102569580078125,0.8486666679382324,0.4195503890514374
|
||||
42,0.8784166574478149,0.31086069345474243,0.8446666598320007,0.415301114320755
|
||||
43,0.8816666603088379,0.3063320219516754,0.8423333168029785,0.44579166173934937
|
||||
44,0.8821666836738586,0.3044925630092621,0.8429999947547913,0.4366433620452881
|
||||
45,0.8818333148956299,0.3025430738925934,0.8339999914169312,0.4812167286872864
|
||||
46,0.8836666941642761,0.3021080493927002,0.8456666469573975,0.4139736592769623
|
||||
47,0.8850833177566528,0.295707106590271,0.8486666679382324,0.4226844906806946
|
||||
48,0.8834999799728394,0.2955981492996216,0.8413333296775818,0.45863327383995056
|
||||
49,0.8835833072662354,0.29366767406463623,0.8529999852180481,0.4104471504688263
|
||||
50,0.8878333568572998,0.28793343901634216,0.7730000019073486,0.6682868599891663
|
||||
51,0.8879166841506958,0.28880414366722107,0.8410000205039978,0.42320355772972107
|
||||
52,0.8888333439826965,0.28470084071159363,0.8463333249092102,0.4198496639728546
|
||||
53,0.8919166922569275,0.28202226758003235,0.8536666631698608,0.41628679633140564
|
||||
54,0.8900833129882812,0.2791743874549866,0.7583333253860474,0.7379936575889587
|
||||
55,0.89083331823349,0.28209903836250305,0.8263333439826965,0.5025476813316345
|
||||
56,0.8914166688919067,0.2790076732635498,0.8493333458900452,0.41152042150497437
|
||||
57,0.8944166898727417,0.27665185928344727,0.8523333072662354,0.4220462143421173
|
||||
58,0.8953333497047424,0.27209198474884033,0.843999981880188,0.4234614670276642
|
||||
59,0.8932499885559082,0.2731625735759735,0.8393333554267883,0.4399682283401489
|
||||
60,0.893833339214325,0.27378541231155396,0.8426666855812073,0.4259805977344513
|
||||
61,0.8951666951179504,0.270453542470932,0.8266666531562805,0.46296101808547974
|
||||
62,0.893750011920929,0.26978862285614014,0.8383333086967468,0.4388676881790161
|
||||
63,0.8979166746139526,0.2648368179798126,0.8486666679382324,0.4405277371406555
|
||||
|
0
as2_Maggioni_Claudio/src/my_vgg16_aug.csv
Normal file
0
as2_Maggioni_Claudio/src/my_vgg16_aug.csv
Normal file
|
|
35
as2_Maggioni_Claudio/src/my_vgg16_noaug.csv
Normal file
35
as2_Maggioni_Claudio/src/my_vgg16_noaug.csv
Normal file
|
|
@ -0,0 +1,35 @@
|
|||
epoch,acc,loss,val_acc,val_loss
|
||||
0,0.5649999976158142,0.955588161945343,0.0,1.6278291940689087
|
||||
1,0.6608333587646484,0.7884675860404968,0.07000000029802322,1.5708225965499878
|
||||
2,0.753333330154419,0.6204149127006531,0.06333333253860474,1.3915884494781494
|
||||
3,0.7858333587646484,0.5166330337524414,0.17000000178813934,1.3135371208190918
|
||||
4,0.8041666746139526,0.4865335524082184,0.10333333164453506,1.3810070753097534
|
||||
5,0.8191666603088379,0.4453645348548889,0.23000000417232513,1.46454918384552
|
||||
6,0.8583333492279053,0.37045857310295105,0.20666666328907013,1.4838533401489258
|
||||
7,0.8816666603088379,0.3096787631511688,0.38999998569488525,1.2644957304000854
|
||||
8,0.9008333086967468,0.2890835702419281,0.5233333110809326,1.0314409732818604
|
||||
9,0.9158333539962769,0.2402680516242981,0.4300000071525574,1.3342552185058594
|
||||
10,0.92166668176651,0.22173365950584412,0.5299999713897705,1.3371758460998535
|
||||
11,0.9208333492279053,0.20474030077457428,0.30666667222976685,1.889732837677002
|
||||
12,0.9291666746139526,0.1892756074666977,0.4833333194255829,1.3816964626312256
|
||||
13,0.9483333230018616,0.14501522481441498,0.44999998807907104,1.5450505018234253
|
||||
14,0.9624999761581421,0.1241658627986908,0.4099999964237213,1.6707463264465332
|
||||
15,0.95333331823349,0.1430375725030899,0.5566666722297668,1.2758015394210815
|
||||
16,0.9483333230018616,0.1334572732448578,0.46000000834465027,1.5948697328567505
|
||||
17,0.9574999809265137,0.12817558646202087,0.43666666746139526,1.7551212310791016
|
||||
18,0.965833306312561,0.09678161144256592,0.4933333396911621,1.5502151250839233
|
||||
19,0.9683333039283752,0.09066082537174225,0.5133333206176758,1.7609212398529053
|
||||
20,0.9758333563804626,0.08929727226495743,0.6399999856948853,1.2165297269821167
|
||||
21,0.9800000190734863,0.07535427808761597,0.4566666781902313,2.07904052734375
|
||||
22,0.9758333563804626,0.08100691437721252,0.4266666769981384,2.1591386795043945
|
||||
23,0.9725000262260437,0.08202476799488068,0.5866666436195374,1.6197659969329834
|
||||
24,0.9775000214576721,0.06814886629581451,0.5133333206176758,1.9039390087127686
|
||||
25,0.9750000238418579,0.06604871153831482,0.41333332657814026,2.4949522018432617
|
||||
26,0.9783333539962769,0.06543738394975662,0.503333330154419,2.129647731781006
|
||||
27,0.9758333563804626,0.07011312991380692,0.4099999964237213,2.689142942428589
|
||||
28,0.9758333563804626,0.08310797810554504,0.5233333110809326,1.7345548868179321
|
||||
29,0.9783333539962769,0.061532020568847656,0.653333306312561,1.3687851428985596
|
||||
30,0.9766666889190674,0.05942004546523094,0.3733333349227905,2.6938610076904297
|
||||
31,0.9800000190734863,0.07085715979337692,0.46666666865348816,2.068704843521118
|
||||
32,0.987500011920929,0.053222622722387314,0.54666668176651,1.8517098426818848
|
||||
33,0.9866666793823242,0.04822404310107231,0.476666659116745,2.0873990058898926
|
||||
|
22
as2_Maggioni_Claudio/src/t_test.py
Normal file
22
as2_Maggioni_Claudio/src/t_test.py
Normal file
|
|
@ -0,0 +1,22 @@
|
|||
import joblib
|
||||
import numpy as np
|
||||
from keras import models
|
||||
import scipy.stats
|
||||
|
||||
# Import the accuracy of both models
|
||||
e_a = 0.7733333110809326 # without augmentation
|
||||
e_b = 0.8999999761581421 # with data augmentation
|
||||
|
||||
# # of data points in both test sets
|
||||
L = 300
|
||||
|
||||
# Compute classification variance for both models
|
||||
s_a = e_a * (1 - e_a)
|
||||
s_b = e_b * (1 - e_b)
|
||||
|
||||
# Compute Student's T-test
|
||||
T = (e_a - e_b) / np.sqrt((s_a / L) + (s_b / L))
|
||||
print("T test:\t\t\t %1.06f" % T)
|
||||
print("P-value:\t\t %1.06f" % (scipy.stats.t.sf(abs(T), df=L) * 2))
|
||||
print("No aug variance:\t %1.06f" % s_a)
|
||||
print("With aug variance:\t %1.06f" % s_b)
|
||||
BIN
as2_Maggioni_Claudio/t1_plot.png
Normal file
BIN
as2_Maggioni_Claudio/t1_plot.png
Normal file
{kind=link}
Binary file not shown.
|
After 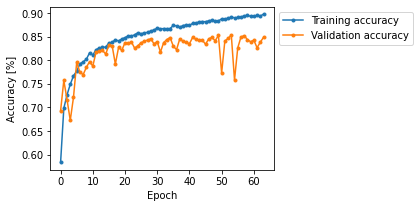
(image error) Size: 17 KiB |
BIN
as2_Maggioni_Claudio/t2_aug.png
Normal file
BIN
as2_Maggioni_Claudio/t2_aug.png
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 15 KiB |
BIN
as2_Maggioni_Claudio/t2_noaug.png
Normal file
BIN
as2_Maggioni_Claudio/t2_noaug.png
Normal file
{kind=link}
Binary file not shown.
|
After 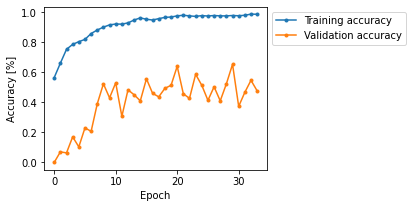
(image error) Size: 15 KiB |
Reference in a new issue