beginning of report
This commit is contained in:
parent
0476edae8a
commit
39a6c59e2c
7 changed files with 2433 additions and 1 deletions
|
|
@ -160,7 +160,7 @@ def main():
|
|||
ax.set(ylabel="Metric value", ylim=[0, 1], xlabel="Metric")
|
||||
ax.set_title("Distribution of metrics for each classifier")
|
||||
sns.despine(offset=10, trim=True)
|
||||
f.savefig(OUT_DIR + '/boxplot.png')
|
||||
f.savefig(OUT_DIR + '/boxplot.svg')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
|
|
|||
22
metric_stats.py
Executable file
22
metric_stats.py
Executable file
|
|
@ -0,0 +1,22 @@
|
|||
#!/usr/bin/env python3
|
||||
|
||||
import pandas as pd
|
||||
import os
|
||||
|
||||
def main():
|
||||
dfs = pd.read_csv(os.path.dirname(__file__) + '/metrics/feature_vectors_labeled.csv')
|
||||
metrics = ['MTH', 'FLD', 'RFC', 'INT', 'SZ', 'CPX', 'EX', 'RET', 'BCM',
|
||||
'NML', 'WRD', 'DCM']
|
||||
df = dfs.agg(dict([(m, ['min', 'max', 'mean']) for m in metrics])).reset_index()
|
||||
df = pd.melt(df, id_vars=['index'], value_vars=metrics, var_name='metric') \
|
||||
.pivot(index='metric', columns=['index'], values=['value']) \
|
||||
.reset_index()
|
||||
df.columns = sorted([c[1] for c in df.columns])
|
||||
df = df.reindex([df.columns[0]] + list(reversed(sorted(df.columns[1:]))), axis=1)
|
||||
print(df.to_markdown(index=False))
|
||||
|
||||
print()
|
||||
print(dfs.groupby('buggy').count().loc[:, 'class_name'])
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
{kind=link}
Binary file not shown.
|
Before 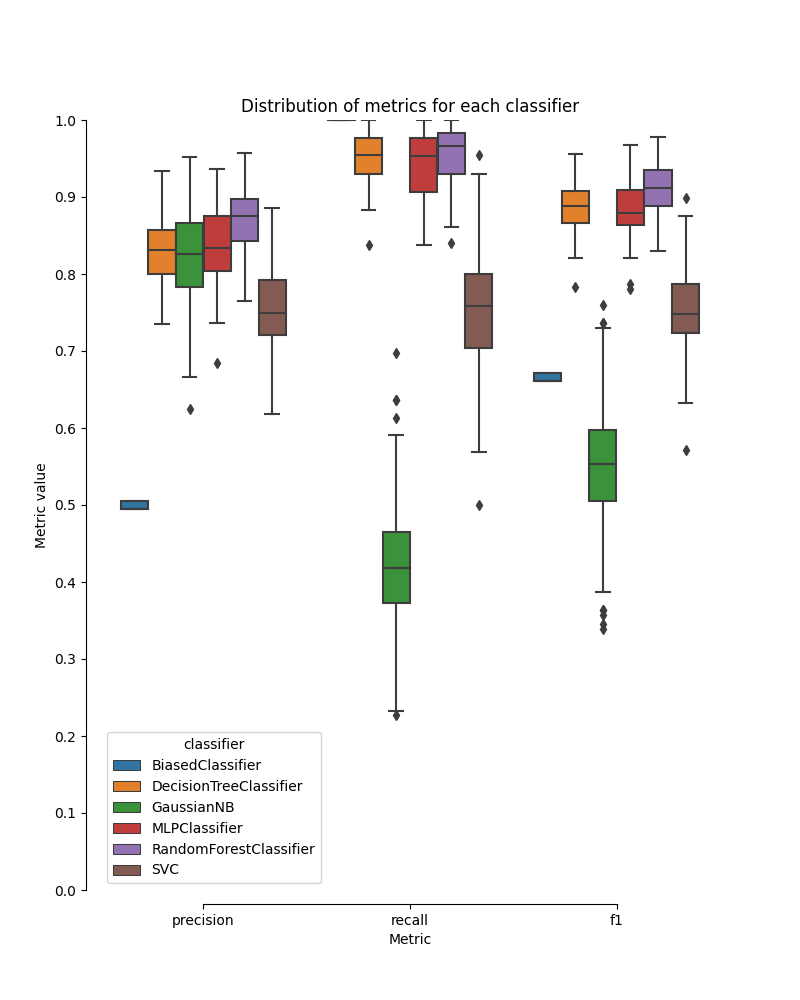
(image error) Size: 45 KiB |
2230
models/boxplot.svg
Normal file
2230
models/boxplot.svg
Normal file
{kind=link}
File diff suppressed because it is too large
Load diff
|
After 
(image error) Size: 64 KiB |
8
report/build.sh
Executable file
8
report/build.sh
Executable file
|
|
@ -0,0 +1,8 @@
|
|||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
|
||||
SCRIPT_DIR=$(cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd)
|
||||
|
||||
cd "$SCRIPT_DIR"
|
||||
pandoc main.md -o main.pdf
|
||||
172
report/main.md
Normal file
172
report/main.md
Normal file
|
|
@ -0,0 +1,172 @@
|
|||
---
|
||||
author: Claudio Maggioni
|
||||
title: Information Modelling & Analysis -- Project 2
|
||||
geometry: margin=2cm,bottom=3cm
|
||||
---
|
||||
|
||||
<!--The following shows a minimal submission report for project 2. If you
|
||||
choose to use this template, replace all template instructions (the
|
||||
yellow bits) with your own values. In addition, for any section, if
|
||||
**and only if** anything was unclear or warnings were raised by the
|
||||
code, and you had to take assumptions about the correct implementation
|
||||
(e.g., about details of a metric), describe your assumptions in one or
|
||||
two sentences.
|
||||
|
||||
You may - at your own risk - also choose not to use this template. As
|
||||
long as your submission is a latex-generated, english PDF containing all
|
||||
expected info, you'll be fine.-->
|
||||
|
||||
# Code Repository
|
||||
|
||||
The code and result files, part of this submission, can be found at
|
||||
|
||||
- Repository: [https://github.com/infoMA2023/project-02-bug-prediction-maggicl](https://github.com/infoMA2023/project-02-bug-prediction-maggicl)
|
||||
- Commit ID: **TBD**
|
||||
|
||||
# Data Pre-Processing
|
||||
|
||||
I use the sources of the [Closure]{.smallcaps} repository that were already downloaded using the command:
|
||||
|
||||
```shell
|
||||
defects4j checkout -p Closure -v 1f -w ./resources
|
||||
```
|
||||
|
||||
and used the code in the following subfolder for the project:
|
||||
|
||||
```
|
||||
./resources/defects4j-checkout-closure-1f/src/com/google/javascript/jscomp/
|
||||
```
|
||||
|
||||
relative to the root folder of the repository. The resulting csv of extracted, labelled feature vectors can be found in
|
||||
the repository at the following path:
|
||||
|
||||
```
|
||||
./metrics/feature_vectors_labeled.csv
|
||||
```
|
||||
|
||||
relative to the root folder of the repository.
|
||||
|
||||
## Feature Vector Extraction
|
||||
|
||||
I extracted **291** feature vectors in total. Aggregate metrics
|
||||
about the extracted feature vectors, i.e. the distribution of the values of each
|
||||
code metric, can be found in Table [1](#tab:metrics){reference-type="ref"
|
||||
reference="tab:metrics"}.
|
||||
|
||||
::: {#tab:metrics}
|
||||
| **Metric** | **Min** | **Average** | **Max** |
|
||||
|:----|------:|-----------:|-------:|
|
||||
| BCM | 0 | 13.4124 | 221 |
|
||||
| CPX | 0 | 5.8247 | 96 |
|
||||
| DCM | 0 | 4.8652 | 176.2 |
|
||||
| EX | 0 | 0.1134 | 2 |
|
||||
| FLD | 0 | 6.5773 | 167 |
|
||||
| INT | 0 | 0.6667 | 3 |
|
||||
| MTH | 0 | 11.6529 | 209 |
|
||||
| NML | 0 | 13.5622 | 28 |
|
||||
| RET | 0 | 3.6735 | 86 |
|
||||
| RFC | 0 | 107.2710 | 882 |
|
||||
| SZ | 0 | 18.9966 | 347 |
|
||||
| WRD | 0 | 314.4740 | 3133 |
|
||||
|
||||
: Distribution of values for each extracted code metric.
|
||||
:::
|
||||
|
||||
## Feature Vector Labelling
|
||||
|
||||
After feature vectors are labeled, I determine that the dataset contains
|
||||
**75** buggy classes and **216** non-buggy classes.
|
||||
|
||||
# Classifiers
|
||||
|
||||
In every subsection below, describe in a concise way which different
|
||||
hyperparameters you tried for the corresponding classifier, and report
|
||||
the corresponding precision, recall and F1 values (for example in a
|
||||
table or an [itemize]{.smallcaps}-environment). Furthermore, for every
|
||||
type of classifiers, explicitly mention which hyperparameter
|
||||
configuration you chose (based on above reported results) to be used in
|
||||
further steps, and (in one or two sentences), explain why these
|
||||
hyperparameters may outperform the other ones you tested..
|
||||
|
||||
## Decision Tree (DT)
|
||||
|
||||
## Naive Bayes (NB)
|
||||
|
||||
## Support Vector Machine (SVP)
|
||||
|
||||
## Multi-Layer Perceptron (MLP)
|
||||
|
||||
## Random Forest (RF)
|
||||
|
||||
# Evaluation
|
||||
|
||||
## Output Distributions
|
||||
|
||||
Add a boxplot showing mean and standard deviation for **Precision**
|
||||
values on all 6 classifiers (5 trained + 1 biased)\
|
||||
Add a boxplot showing mean and standard deviation for **Recall** values
|
||||
on all 6 classifiers (5 trained + 1 biased)\
|
||||
Add a boxplot showing mean and standard deviation for **F1** values on
|
||||
all 6 classifiers (5 trained + 1 biased)
|
||||
|
||||
{#fig:boxplot}
|
||||
|
||||
## Comparison and Significance
|
||||
|
||||
For every combination of two classifiers and every performance metric
|
||||
(precision, recall, f1) compare which algorithm performs better, by how
|
||||
much, and report the corresponding p-value in the following
|
||||
subsubsections:
|
||||
|
||||
::: {#tab:precision}
|
||||
| | DecisionTreeClassifier | GaussianNB | MLPClassifier | RandomForestClassifier | SVC |
|
||||
|:-----------------------|:-------------------------|:-------------|:----------------|:-------------------------|------:|
|
||||
| BiasedClassifier | 0 | 0 | 0 | 0 | 0 |
|
||||
| DecisionTreeClassifier | -- | 0.0893 | 0.4012 | 0 | 0 |
|
||||
| GaussianNB | -- | -- | 0.0348 | 0 | 0 |
|
||||
| MLPClassifier | -- | -- | -- | 0 | 0 |
|
||||
| RandomForestClassifier | -- | -- | -- | -- | 0 |
|
||||
|
||||
: Pairwise Wilcoxon test for precision for each combination of classifiers.
|
||||
:::
|
||||
|
||||
::: {#tab:recall}
|
||||
| | DecisionTreeClassifier | GaussianNB | MLPClassifier | RandomForestClassifier | SVC |
|
||||
|:-----------------------|:-------------------------|:-------------|:----------------|:-------------------------|------:|
|
||||
| BiasedClassifier | 0 | 0 | 0 | 0 | 0 |
|
||||
| DecisionTreeClassifier | -- | 0 | 0.0118 | 0.3276 | 0 |
|
||||
| GaussianNB | -- | -- | 0 | 0 | 0 |
|
||||
| MLPClassifier | -- | -- | -- | 0.0001 | 0 |
|
||||
| RandomForestClassifier | -- | -- | -- | -- | 0 |
|
||||
: Pairwise Wilcoxon test for recall for each combination of classifiers.
|
||||
:::
|
||||
|
||||
::: {#tab:f1}
|
||||
| | DecisionTreeClassifier | GaussianNB | MLPClassifier | RandomForestClassifier | SVC |
|
||||
|:-----------------------|:-------------------------|:-------------|:----------------|:-------------------------|------:|
|
||||
| BiasedClassifier | 0 | 0 | 0 | 0 | 0 |
|
||||
| DecisionTreeClassifier | -- | 0 | 0.4711 | 0 | 0 |
|
||||
| GaussianNB | -- | -- | 0 | 0 | 0 |
|
||||
| MLPClassifier | -- | -- | -- | 0 | 0 |
|
||||
| RandomForestClassifier | -- | -- | -- | -- | 0 |
|
||||
: Pairwise Wilcoxon test for the F1 score metric for each combination of classifiers.
|
||||
:::
|
||||
|
||||
### F1 Values
|
||||
|
||||
-
|
||||
|
||||
- \...
|
||||
|
||||
### Precision
|
||||
|
||||
(same as for F1 above)
|
||||
|
||||
### Recall
|
||||
|
||||
(same as for F1 above)
|
||||
|
||||
## Practical Usefulness
|
||||
|
||||
Discuss the practical usefulness of the obtained classifiers in a
|
||||
realistic bug prediction scenario (1 paragraph).
|
||||
BIN
report/main.pdf
Normal file
BIN
report/main.pdf
Normal file
Binary file not shown.
Reference in a new issue