Report section 1 and 2 done
This commit is contained in:
parent
fd007afb60
commit
43437c2bed
8 changed files with 493 additions and 30 deletions
302
.gitignore
vendored
302
.gitignore
vendored
|
|
@ -1,4 +1,3 @@
|
||||||
env/
|
|
||||||
# Byte-compiled / optimized / DLL files
|
# Byte-compiled / optimized / DLL files
|
||||||
__pycache__/
|
__pycache__/
|
||||||
*.py[cod]
|
*.py[cod]
|
||||||
|
|
@ -158,4 +157,303 @@ cython_debug/
|
||||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||||
.idea/
|
.idea/
|
||||||
|
**/.DS_Store
|
||||||
|
out/model/*.pt
|
||||||
|
|
||||||
|
## Core latex/pdflatex auxiliary files:
|
||||||
|
*.aux
|
||||||
|
*.lof
|
||||||
|
*.lot
|
||||||
|
*.fls
|
||||||
|
*.out
|
||||||
|
*.toc
|
||||||
|
*.fmt
|
||||||
|
*.fot
|
||||||
|
*.cb
|
||||||
|
*.cb2
|
||||||
|
.*.lb
|
||||||
|
|
||||||
|
## Intermediate documents:
|
||||||
|
*.dvi
|
||||||
|
*.xdv
|
||||||
|
*-converted-to.*
|
||||||
|
# these rules might exclude image files for figures etc.
|
||||||
|
# *.ps
|
||||||
|
# *.eps
|
||||||
|
# *.pdf
|
||||||
|
|
||||||
|
## Generated if empty string is given at "Please type another file name for output:"
|
||||||
|
|
||||||
|
## Bibliography auxiliary files (bibtex/biblatex/biber):
|
||||||
|
*.bbl
|
||||||
|
*.bcf
|
||||||
|
*.blg
|
||||||
|
*-blx.aux
|
||||||
|
*-blx.bib
|
||||||
|
*.run.xml
|
||||||
|
|
||||||
|
## Build tool auxiliary files:
|
||||||
|
*.fdb_latexmk
|
||||||
|
*.synctex
|
||||||
|
*.synctex(busy)
|
||||||
|
*.synctex.gz
|
||||||
|
*.synctex.gz(busy)
|
||||||
|
*.pdfsync
|
||||||
|
|
||||||
|
## Build tool directories for auxiliary files
|
||||||
|
# latexrun
|
||||||
|
latex.out/
|
||||||
|
|
||||||
|
## Auxiliary and intermediate files from other packages:
|
||||||
|
# algorithms
|
||||||
|
*.alg
|
||||||
|
*.loa
|
||||||
|
|
||||||
|
# achemso
|
||||||
|
acs-*.bib
|
||||||
|
|
||||||
|
# amsthm
|
||||||
|
*.thm
|
||||||
|
|
||||||
|
# beamer
|
||||||
|
*.nav
|
||||||
|
*.pre
|
||||||
|
*.snm
|
||||||
|
*.vrb
|
||||||
|
|
||||||
|
# changes
|
||||||
|
*.soc
|
||||||
|
|
||||||
|
# comment
|
||||||
|
*.cut
|
||||||
|
|
||||||
|
# cprotect
|
||||||
|
*.cpt
|
||||||
|
|
||||||
|
# elsarticle (documentclass of Elsevier journals)
|
||||||
|
*.spl
|
||||||
|
|
||||||
|
# endnotes
|
||||||
|
*.ent
|
||||||
|
|
||||||
|
*.lox
|
||||||
|
|
||||||
|
# feynmf/feynmp
|
||||||
|
*.mf
|
||||||
|
*.mp
|
||||||
|
*.t[1-9]
|
||||||
|
*.t[1-9][0-9]
|
||||||
|
*.tfm
|
||||||
|
|
||||||
|
#(r)(e)ledmac/(r)(e)ledpar
|
||||||
|
*.end
|
||||||
|
*.?end
|
||||||
|
*.[1-9]
|
||||||
|
*.[1-9][0-9]
|
||||||
|
*.[1-9][0-9][0-9]
|
||||||
|
*.[1-9]R
|
||||||
|
*.[1-9][0-9]R
|
||||||
|
*.[1-9][0-9][0-9]R
|
||||||
|
*.eledsec[1-9]
|
||||||
|
*.eledsec[1-9]R
|
||||||
|
*.eledsec[1-9][0-9]
|
||||||
|
*.eledsec[1-9][0-9]R
|
||||||
|
*.eledsec[1-9][0-9][0-9]
|
||||||
|
*.eledsec[1-9][0-9][0-9]R
|
||||||
|
|
||||||
|
# glossaries
|
||||||
|
*.acn
|
||||||
|
*.acr
|
||||||
|
*.glg
|
||||||
|
*.glo
|
||||||
|
*.gls
|
||||||
|
*.glsdefs
|
||||||
|
*.lzo
|
||||||
|
*.lzs
|
||||||
|
*.slg
|
||||||
|
*.slo
|
||||||
|
*.sls
|
||||||
|
|
||||||
|
# uncomment this for glossaries-extra (will ignore makeindex's style files!)
|
||||||
|
# *.ist
|
||||||
|
|
||||||
|
# gnuplot
|
||||||
|
*.gnuplot
|
||||||
|
*.table
|
||||||
|
|
||||||
|
# gnuplottex
|
||||||
|
*-gnuplottex-*
|
||||||
|
|
||||||
|
# gregoriotex
|
||||||
|
*.gaux
|
||||||
|
*.glog
|
||||||
|
*.gtex
|
||||||
|
|
||||||
|
# htlatex
|
||||||
|
*.4ct
|
||||||
|
*.4tc
|
||||||
|
*.idv
|
||||||
|
*.lg
|
||||||
|
*.trc
|
||||||
|
*.xref
|
||||||
|
|
||||||
|
# hyperref
|
||||||
|
*.brf
|
||||||
|
|
||||||
|
# knitr
|
||||||
|
*-concordance.tex
|
||||||
|
# *.tikz
|
||||||
|
*-tikzDictionary
|
||||||
|
|
||||||
|
# listings
|
||||||
|
*.lol
|
||||||
|
|
||||||
|
# luatexja-ruby
|
||||||
|
*.ltjruby
|
||||||
|
|
||||||
|
# makeidx
|
||||||
|
*.idx
|
||||||
|
*.ilg
|
||||||
|
*.ind
|
||||||
|
|
||||||
|
# minitoc
|
||||||
|
*.maf
|
||||||
|
*.mlf
|
||||||
|
*.mlt
|
||||||
|
*.mtc[0-9]*
|
||||||
|
*.slf[0-9]*
|
||||||
|
*.slt[0-9]*
|
||||||
|
*.stc[0-9]*
|
||||||
|
|
||||||
|
# minted
|
||||||
|
_minted*
|
||||||
|
*.pyg
|
||||||
|
|
||||||
|
# morewrites
|
||||||
|
*.mw
|
||||||
|
|
||||||
|
# newpax
|
||||||
|
*.newpax
|
||||||
|
|
||||||
|
# nomencl
|
||||||
|
*.nlg
|
||||||
|
*.nlo
|
||||||
|
*.nls
|
||||||
|
|
||||||
|
# pax
|
||||||
|
*.pax
|
||||||
|
|
||||||
|
# pdfpcnotes
|
||||||
|
*.pdfpc
|
||||||
|
|
||||||
|
# sagetex
|
||||||
|
*.sagetex.sage
|
||||||
|
*.sagetex.py
|
||||||
|
*.sagetex.scmd
|
||||||
|
|
||||||
|
# scrwfile
|
||||||
|
*.wrt
|
||||||
|
|
||||||
|
# svg
|
||||||
|
svg-inkscape/
|
||||||
|
|
||||||
|
# sympy
|
||||||
|
*.sout
|
||||||
|
*.sympy
|
||||||
|
sympy-plots-for-*.tex/
|
||||||
|
|
||||||
|
# pdfcomment
|
||||||
|
*.upa
|
||||||
|
*.upb
|
||||||
|
|
||||||
|
# pythontex
|
||||||
|
*.pytxcode
|
||||||
|
pythontex-files-*/
|
||||||
|
|
||||||
|
# tcolorbox
|
||||||
|
*.listing
|
||||||
|
|
||||||
|
# thmtools
|
||||||
|
*.loe
|
||||||
|
|
||||||
|
# TikZ & PGF
|
||||||
|
*.dpth
|
||||||
|
*.md5
|
||||||
|
*.auxlock
|
||||||
|
|
||||||
|
# titletoc
|
||||||
|
*.ptc
|
||||||
|
|
||||||
|
# todonotes
|
||||||
|
*.tdo
|
||||||
|
|
||||||
|
# vhistory
|
||||||
|
*.hst
|
||||||
|
*.ver
|
||||||
|
|
||||||
|
*.lod
|
||||||
|
|
||||||
|
# xcolor
|
||||||
|
*.xcp
|
||||||
|
|
||||||
|
# xmpincl
|
||||||
|
*.xmpi
|
||||||
|
|
||||||
|
# xindy
|
||||||
|
*.xdy
|
||||||
|
|
||||||
|
# xypic precompiled matrices and outlines
|
||||||
|
*.xyc
|
||||||
|
*.xyd
|
||||||
|
|
||||||
|
# endfloat
|
||||||
|
*.ttt
|
||||||
|
*.fff
|
||||||
|
|
||||||
|
# Latexian
|
||||||
|
TSWLatexianTemp*
|
||||||
|
|
||||||
|
## Editors:
|
||||||
|
# WinEdt
|
||||||
|
*.bak
|
||||||
|
*.sav
|
||||||
|
|
||||||
|
# Texpad
|
||||||
|
.texpadtmp
|
||||||
|
|
||||||
|
# LyX
|
||||||
|
*.lyx~
|
||||||
|
|
||||||
|
# Kile
|
||||||
|
*.backup
|
||||||
|
|
||||||
|
# gummi
|
||||||
|
.*.swp
|
||||||
|
|
||||||
|
# KBibTeX
|
||||||
|
*~[0-9]*
|
||||||
|
|
||||||
|
# TeXnicCenter
|
||||||
|
*.tps
|
||||||
|
|
||||||
|
# auto folder when using emacs and auctex
|
||||||
|
./auto/*
|
||||||
|
*.el
|
||||||
|
|
||||||
|
# expex forward references with \gathertags
|
||||||
|
*-tags.tex
|
||||||
|
|
||||||
|
# standalone packages
|
||||||
|
*.sta
|
||||||
|
|
||||||
|
# Makeindex log files
|
||||||
|
*.lpz
|
||||||
|
|
||||||
|
# xwatermark package
|
||||||
|
*.xwm
|
||||||
|
|
||||||
|
# REVTeX puts footnotes in the bibliography by default, unless the nofootinbib
|
||||||
|
# option is specified. Footnotes are the stored in a file with suffix Notes.bib.
|
||||||
|
# Uncomment the next line to have this generated file ignored.
|
||||||
|
#*Notes.bib
|
||||||
10
README.md
10
README.md
|
|
@ -69,3 +69,13 @@ performance of the classifiers in terms of average precision and recall, which a
|
||||||
| freq | 27.00% | 40.00% |
|
| freq | 27.00% | 40.00% |
|
||||||
| lsi | 4.00% | 20.00% |
|
| lsi | 4.00% | 20.00% |
|
||||||
| doc2vec | 10.00% | 10.00% |
|
| doc2vec | 10.00% | 10.00% |
|
||||||
|
|
||||||
|
## Report
|
||||||
|
|
||||||
|
To compile the report run:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
cd report
|
||||||
|
pdflatex -interaction=nonstopmode -output-directory=. main.tex
|
||||||
|
pdflatex -interaction=nonstopmode -output-directory=. main.tex
|
||||||
|
```
|
||||||
{kind=link}
Binary file not shown.
|
Before 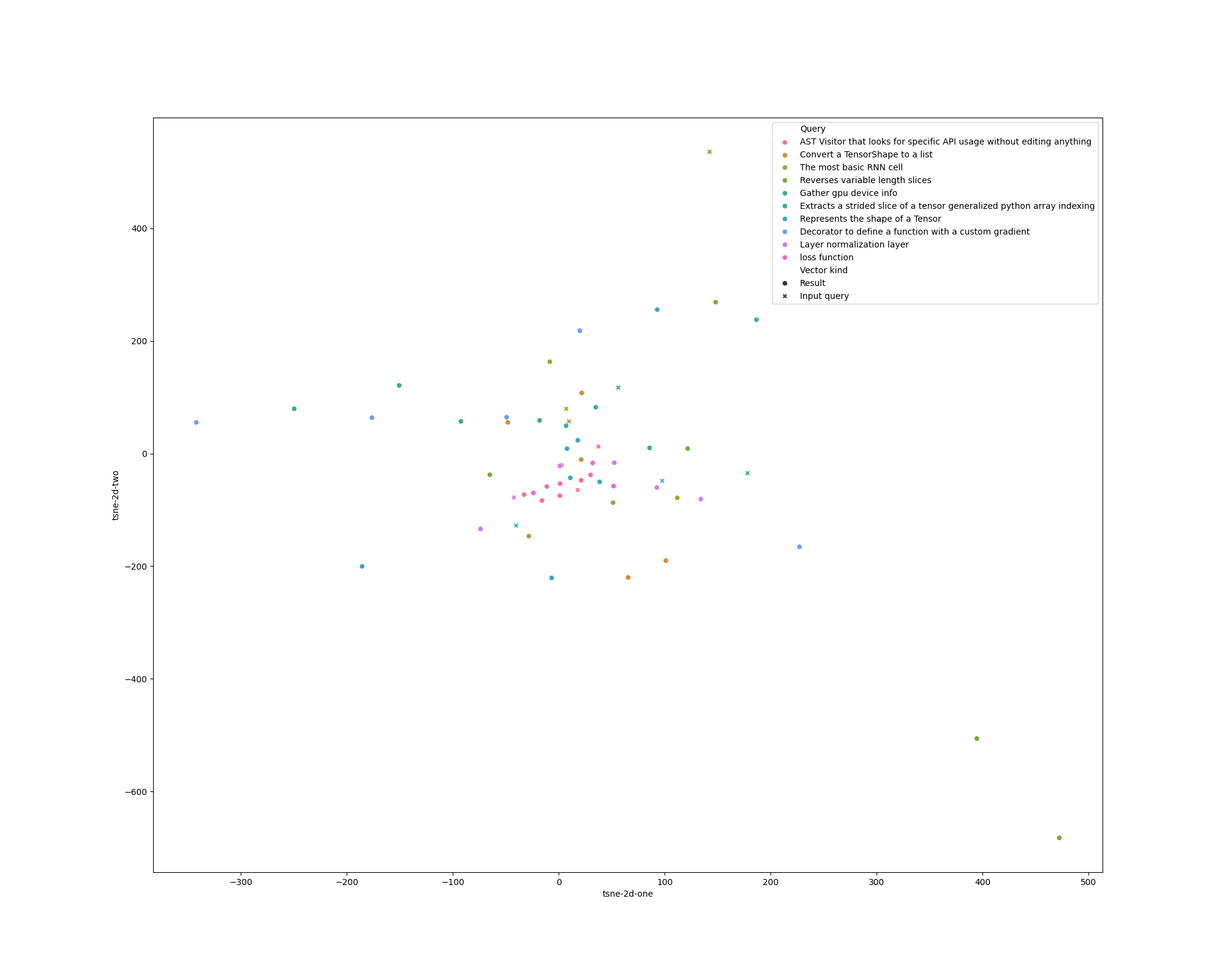
(image error) Size: 89 KiB After 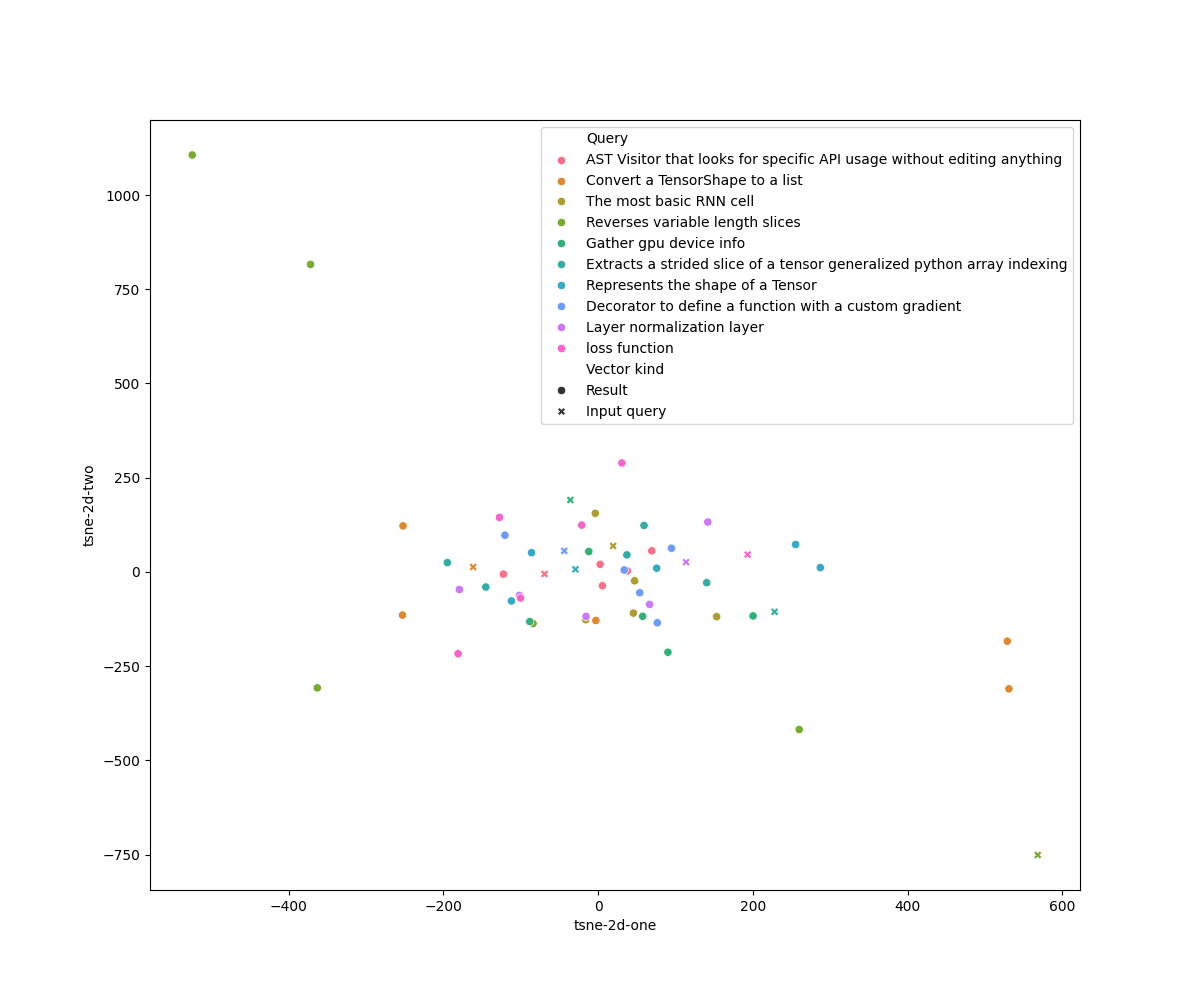
(image error) Size: 78 KiB
|
BIN
out/lsi_plot.png
BIN
out/lsi_plot.png
{kind=link}
Binary file not shown.
|
Before 
(image error) Size: 79 KiB After 
(image error) Size: 69 KiB
|
|
|
@ -1,2 +1,2 @@
|
||||||
Precision: 4.00%
|
Precision: 4.50%
|
||||||
Recall: 20.00%
|
Recall: 20.00%
|
||||||
|
|
|
||||||
|
|
@ -107,7 +107,7 @@ def evaluate(method_name: str, file_path: str) -> tuple[float, float]:
|
||||||
|
|
||||||
if len(dfs) > 0:
|
if len(dfs) > 0:
|
||||||
df = pd.concat(dfs)
|
df = pd.concat(dfs)
|
||||||
plt.figure(figsize=(20, 16))
|
plt.figure(figsize=(12, 10))
|
||||||
sns.scatterplot(
|
sns.scatterplot(
|
||||||
x="tsne-2d-one", y="tsne-2d-two",
|
x="tsne-2d-one", y="tsne-2d-two",
|
||||||
hue="Query",
|
hue="Query",
|
||||||
|
|
|
||||||
BIN
report/main.pdf
Normal file
BIN
report/main.pdf
Normal file
Binary file not shown.
207
report/main.tex
207
report/main.tex
|
|
@ -16,7 +16,7 @@
|
||||||
\usepackage{multicol}
|
\usepackage{multicol}
|
||||||
\usepackage{multirow}
|
\usepackage{multirow}
|
||||||
\usepackage{pbox}
|
\usepackage{pbox}
|
||||||
\usepackage{enumitem}
|
\usepackage{enumitem}
|
||||||
\usepackage{colortbl}
|
\usepackage{colortbl}
|
||||||
\usepackage{pifont}
|
\usepackage{pifont}
|
||||||
\usepackage{xspace}
|
\usepackage{xspace}
|
||||||
|
|
@ -28,7 +28,6 @@
|
||||||
\usepackage{color}
|
\usepackage{color}
|
||||||
\usepackage{anyfontsize}
|
\usepackage{anyfontsize}
|
||||||
\usepackage{comment}
|
\usepackage{comment}
|
||||||
\usepackage{soul}
|
|
||||||
\usepackage{multibib}
|
\usepackage{multibib}
|
||||||
\usepackage{float}
|
\usepackage{float}
|
||||||
\usepackage{caption}
|
\usepackage{caption}
|
||||||
|
|
@ -47,23 +46,22 @@
|
||||||
|
|
||||||
\subsection*{Section 1 - Data Extraction}
|
\subsection*{Section 1 - Data Extraction}
|
||||||
|
|
||||||
The data extraction process scans through the files in the TensorFlow project to extract Python docstrings and symbol
|
The data extraction (implemented in the script \texttt{extract-data.py}) process scans through the files in the
|
||||||
names for functions, classes and methods. A summary of the number of features extracted can be found in
|
TensorFlow project to extract Python docstrings and symbol names for functions, classes and methods. A summary of the
|
||||||
table~\ref{tab:count1}.
|
number of features extracted can be found in table~\ref{tab:count1}. The collected figures show that the number of
|
||||||
|
classes is more than half the number of files, while the number of functions is about twice the number of files.
|
||||||
Report and comment figures about the extracted data (e.g., number of files; number of code
|
Additionally, the data shows that a class has slightly more than 2 methods in it on average.
|
||||||
entities of different kinds).
|
|
||||||
|
|
||||||
\begin{table}[H]
|
\begin{table}[H]
|
||||||
\centering \scriptsize
|
\centering
|
||||||
\begin{tabular}{cccc}
|
\begin{tabular}{cc}
|
||||||
\hline
|
\hline
|
||||||
Type & Number \\
|
Type & Number \\
|
||||||
\hline
|
\hline
|
||||||
Python files & ? \\
|
Python files & 2817 \\
|
||||||
Classes & ? \\
|
Classes & 1882 \\
|
||||||
Functions & ? \\
|
Functions & 4565 \\
|
||||||
Methods & ? \\
|
Methods & 5817 \\
|
||||||
\hline
|
\hline
|
||||||
\end{tabular}
|
\end{tabular}
|
||||||
\caption{Count of created classes and properties.}
|
\caption{Count of created classes and properties.}
|
||||||
|
|
@ -72,39 +70,196 @@ Methods & ? \\
|
||||||
|
|
||||||
\subsection*{Section 2: Training of search engines}
|
\subsection*{Section 2: Training of search engines}
|
||||||
|
|
||||||
Report and comment an example of a query and the results.
|
The training and model execution of the search engines is implemented in the Python script \texttt{search-data.py}.
|
||||||
|
The script is able to search a given natural language query among the extracted TensorFlow corpus using four techniques.
|
||||||
|
These are namely: Word Frequency Similarity, Term-Frequency Inverse Document-Frequency (TF-IDF) Similarity, Latent
|
||||||
|
Semantic Indexing (LSI), and Doc2Vec.
|
||||||
|
|
||||||
|
An example output of results generated from the query ``Gather gpu device info'' for the word frequency, TF-IDF, LSI
|
||||||
|
and Doc2Vec models are shown in
|
||||||
|
figures~\ref{fig:search-freq},~\ref{fig:search-tfidf},~\ref{fig:search-lsi}~and~\ref{fig:search-doc2vec} respectively.
|
||||||
|
Both the word frequency and TF-IDF model identify the correct result (according to the provided ground truth for this
|
||||||
|
query) as the first recommendation to output. Both the LSI and Doc2Vec models fail to report the correct function in
|
||||||
|
all 5 results.
|
||||||
|
|
||||||
\subsection*{Section 3: Evaluation of search engines}
|
\begin{figure}
|
||||||
|
\small
|
||||||
|
\begin{verbatim}
|
||||||
|
Similarity: 87.29%
|
||||||
|
Python function: gather_gpu_devices
|
||||||
|
Description: Gather gpu device info. Returns: A list of test_log_pb2.GPUInf...
|
||||||
|
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||||
|
Line: 167
|
||||||
|
|
||||||
Using the ground truth provided, evaluate and report recall and average precision for each of the four search engines; comment the differences among search engines.
|
Similarity: 60.63%
|
||||||
|
Python function: compute_capability_from_device_desc
|
||||||
|
Description: Returns the GpuInfo given a DeviceAttributes proto. Args: devi...
|
||||||
|
File: tensorflow/tensorflow/python/framework/gpu_util.py
|
||||||
|
Line: 35
|
||||||
|
|
||||||
|
Similarity: 60.30%
|
||||||
|
Python function: gpu_device_name
|
||||||
|
Description: Returns the name of a GPU device if available or the empty str...
|
||||||
|
File: tensorflow/tensorflow/python/framework/test_util.py
|
||||||
|
Line: 129
|
||||||
|
|
||||||
|
Similarity: 58.83%
|
||||||
|
Python function: gather_available_device_info
|
||||||
|
Description: Gather list of devices available to TensorFlow. Returns: A lis...
|
||||||
|
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||||
|
Line: 126
|
||||||
|
|
||||||
|
Similarity: 57.74%
|
||||||
|
Python function: gather_memory_info
|
||||||
|
Description: Gather memory info.
|
||||||
|
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||||
|
Line: 70
|
||||||
|
\end{verbatim}
|
||||||
|
\caption{Search result output for the query ``Gather gpu device info'' using the word frequency similarity model.}
|
||||||
|
\label{fig:search-freq}
|
||||||
|
\end{figure}
|
||||||
|
|
||||||
|
\begin{figure}
|
||||||
|
\small
|
||||||
|
\begin{verbatim}
|
||||||
|
Similarity: 86.62%
|
||||||
|
Python function: gather_gpu_devices
|
||||||
|
Description: Gather gpu device info. Returns: A list of test_log_pb2.GPUInf...
|
||||||
|
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||||
|
Line: 167
|
||||||
|
|
||||||
|
Similarity: 66.14%
|
||||||
|
Python function: gather_memory_info
|
||||||
|
Description: Gather memory info.
|
||||||
|
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||||
|
Line: 70
|
||||||
|
|
||||||
|
Similarity: 62.52%
|
||||||
|
Python function: gather_available_device_info
|
||||||
|
Description: Gather list of devices available to TensorFlow. Returns: A lis...
|
||||||
|
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||||
|
Line: 126
|
||||||
|
|
||||||
|
Similarity: 57.98%
|
||||||
|
Python function: gather
|
||||||
|
File: tensorflow/tensorflow/compiler/tf2xla/python/xla.py
|
||||||
|
Line: 452
|
||||||
|
|
||||||
|
Similarity: 57.98%
|
||||||
|
Python function: gather_v2
|
||||||
|
File: tensorflow/tensorflow/python/ops/array_ops.py
|
||||||
|
Line: 4736
|
||||||
|
\end{verbatim}
|
||||||
|
\caption{Search result output for the query ``Gather gpu device info'' using the TF-IDF model.}
|
||||||
|
\label{fig:search-tfidf}
|
||||||
|
\end{figure}
|
||||||
|
|
||||||
|
\begin{figure}
|
||||||
|
\small
|
||||||
|
\begin{verbatim}
|
||||||
|
Similarity: 92.11%
|
||||||
|
Python function: device
|
||||||
|
Description: Uses gpu when requested and available.
|
||||||
|
File: tensorflow/tensorflow/python/framework/test_util.py
|
||||||
|
Line: 1581
|
||||||
|
|
||||||
|
Similarity: 92.11%
|
||||||
|
Python function: device
|
||||||
|
Description: Uses gpu when requested and available.
|
||||||
|
File: tensorflow/tensorflow/python/keras/testing_utils.py
|
||||||
|
Line: 925
|
||||||
|
|
||||||
|
Similarity: 89.04%
|
||||||
|
Python function: compute_capability_from_device_desc
|
||||||
|
Description: Returns the GpuInfo given a DeviceAttributes proto. Args: devi...
|
||||||
|
File: tensorflow/tensorflow/python/framework/gpu_util.py
|
||||||
|
Line: 35
|
||||||
|
|
||||||
|
Similarity: 85.96%
|
||||||
|
Python class: CUDADeviceProperties
|
||||||
|
File: tensorflow/tensorflow/tools/test/gpu_info_lib.py
|
||||||
|
Line: 51
|
||||||
|
|
||||||
|
Similarity: 85.93%
|
||||||
|
Python function: gpu_device_name
|
||||||
|
Description: Returns the name of a GPU device if available or the empty str...
|
||||||
|
File: tensorflow/tensorflow/python/framework/test_util.py
|
||||||
|
Line: 129
|
||||||
|
\end{verbatim}
|
||||||
|
\caption{Search result output for the query ``Gather gpu device info'' using the LSI model.}
|
||||||
|
\label{fig:search-lsi}
|
||||||
|
\end{figure}
|
||||||
|
|
||||||
|
\begin{figure}
|
||||||
|
\small
|
||||||
|
\begin{verbatim}
|
||||||
|
Similarity: 81.85%
|
||||||
|
Python method: benchmark_gather_nd_op
|
||||||
|
File: tensorflow/tensorflow/python/kernel_tests/gather_nd_op_test.py
|
||||||
|
Line: 389
|
||||||
|
|
||||||
|
Similarity: 81.83%
|
||||||
|
Python function: gather_hostname
|
||||||
|
File: tensorflow/tensorflow/tools/test/system_info_lib.py
|
||||||
|
Line: 66
|
||||||
|
|
||||||
|
Similarity: 81.07%
|
||||||
|
Python method: benchmarkNontrivialGatherAxis1XLA
|
||||||
|
File: tensorflow/tensorflow/compiler/tests/gather_test.py
|
||||||
|
Line: 210
|
||||||
|
|
||||||
|
Similarity: 80.53%
|
||||||
|
Python method: benchmarkNontrivialGatherAxis4
|
||||||
|
File: tensorflow/tensorflow/compiler/tests/gather_test.py
|
||||||
|
Line: 213
|
||||||
|
|
||||||
|
Similarity: 80.45%
|
||||||
|
Python method: benchmarkNontrivialGatherAxis4XLA
|
||||||
|
File: tensorflow/tensorflow/compiler/tests/gather_test.py
|
||||||
|
Line: 216
|
||||||
|
\end{verbatim}
|
||||||
|
\caption{Search result output for the query ``Gather gpu device info'' using the Doc2Vec model.}
|
||||||
|
\label{fig:search-doc2vec}
|
||||||
|
\end{figure}
|
||||||
|
|
||||||
|
\subsection*{TBD Section 3: Evaluation of search engines}
|
||||||
|
|
||||||
|
Using the ground truth provided, evaluate and report recall and average precision for each of the four search engines;
|
||||||
|
comment the differences among search engines.
|
||||||
|
|
||||||
\begin{table} [H]
|
\begin{table} [H]
|
||||||
\centering \scriptsize
|
\centering
|
||||||
\begin{tabular}{cccc}
|
\begin{tabular}{cccc}
|
||||||
\hline
|
\hline
|
||||||
Engine & Avg Precision & Recall \\
|
Engine & Avg Precision & Recall \\
|
||||||
\hline
|
\hline
|
||||||
Frequencies & ? & ? \\
|
Frequencies & 27.00\% & 40.00\% \\
|
||||||
TD-IDF & ? & ? \\
|
TD-IDF & 20.00\% & 20.00\% \\
|
||||||
LSI & ? & ? \\
|
LSI & 4.00\% & 20.00\% \\
|
||||||
Doc2Vec & ? & ? \\
|
Doc2Vec & 10.00\% & 10.00\% \\
|
||||||
\hline
|
\hline
|
||||||
\end{tabular}
|
\end{tabular}
|
||||||
\caption{Evaluation of search engines.}
|
\caption{Evaluation of search engines.}
|
||||||
\label{tab:tab2}
|
\label{tab:tab2}
|
||||||
\end{table}
|
\end{table}
|
||||||
|
|
||||||
\subsection*{Section 4: Visualisation of query results}
|
\subsection*{TBD Section 4: Visualisation of query results}
|
||||||
|
|
||||||
Include, comment and compare the t-SNE plots for LSI and for Doc2Vec.
|
Include, comment and compare the t-SNE plots for LSI and for Doc2Vec.
|
||||||
|
|
||||||
\begin{figure}[H]
|
\begin{figure}[H]
|
||||||
\begin{center}
|
\begin{center}
|
||||||
\includegraphics[width=0.3\textwidth]{Figures/dummy_pic.png}
|
\includegraphics[width=\textwidth]{../out/doc2vec_plot}
|
||||||
\caption{Caption.}
|
\caption{T-SNE plot for the Doc2Vec model over the queries and ground truths given in \texttt{ground-truth-unique.txt}.}
|
||||||
\label{fig:fig1}
|
\label{fig:tsne-doc2vec}
|
||||||
|
\end{center}
|
||||||
|
\end{figure}
|
||||||
|
|
||||||
|
\begin{figure}[H]
|
||||||
|
\begin{center}
|
||||||
|
\includegraphics[width=\textwidth]{../out/lsi_plot}
|
||||||
|
\caption{T-SNE plot for the LSI model over the queries and ground truths given in \texttt{ground-truth-unique.txt}.}
|
||||||
|
\label{fig:lsi-doc2vec}
|
||||||
\end{center}
|
\end{center}
|
||||||
\end{figure}
|
\end{figure}
|
||||||
\end{document}
|
\end{document}
|
||||||
|
|
|
||||||
Loading…
Reference in a new issue