3 KiB
| author | title | geometry |
|---|---|---|
| Claudio Maggioni | Visual Analytics -- Assignment 2 -- Part 2 | margin=2cm,bottom=3cm |
changequote({{', }}')
Indexing
Similarly to part 1 of the assignment, the first step of indexing is to convert
the newly given CSV dataset (stored in data/restaurants_extended.csv) into a
JSON-lines file which can be directly used as the HTTP request body of
Elasticsearch document insertion requests.
The conversion is performed by the script ./convert.sh. The converted file
is stored in the JSON-lines file data/restaurants_extended.jsonl.
The sources of ./convert.sh are listed below:
include({{../convert.sh}})
The only change in the script is the way the field containing the restaurant
location is parsed. In the extended dataset, city, country and continent are in
this field and separated by /. The script maps the three values in separate
fields and additionally maps the entire string to an additional cityRaw field
which is used in the generation of the runtime field for part 2.
The sourced of the updated upload script, loading the new index are listed below:
include({{../upload.sh}})
Mappings are stored in mappings.json and are identical to the ones in Part 1
other than for the new location fields and their .keyword counterparts
similarly generated as the old city field.
9499 documents are imported.
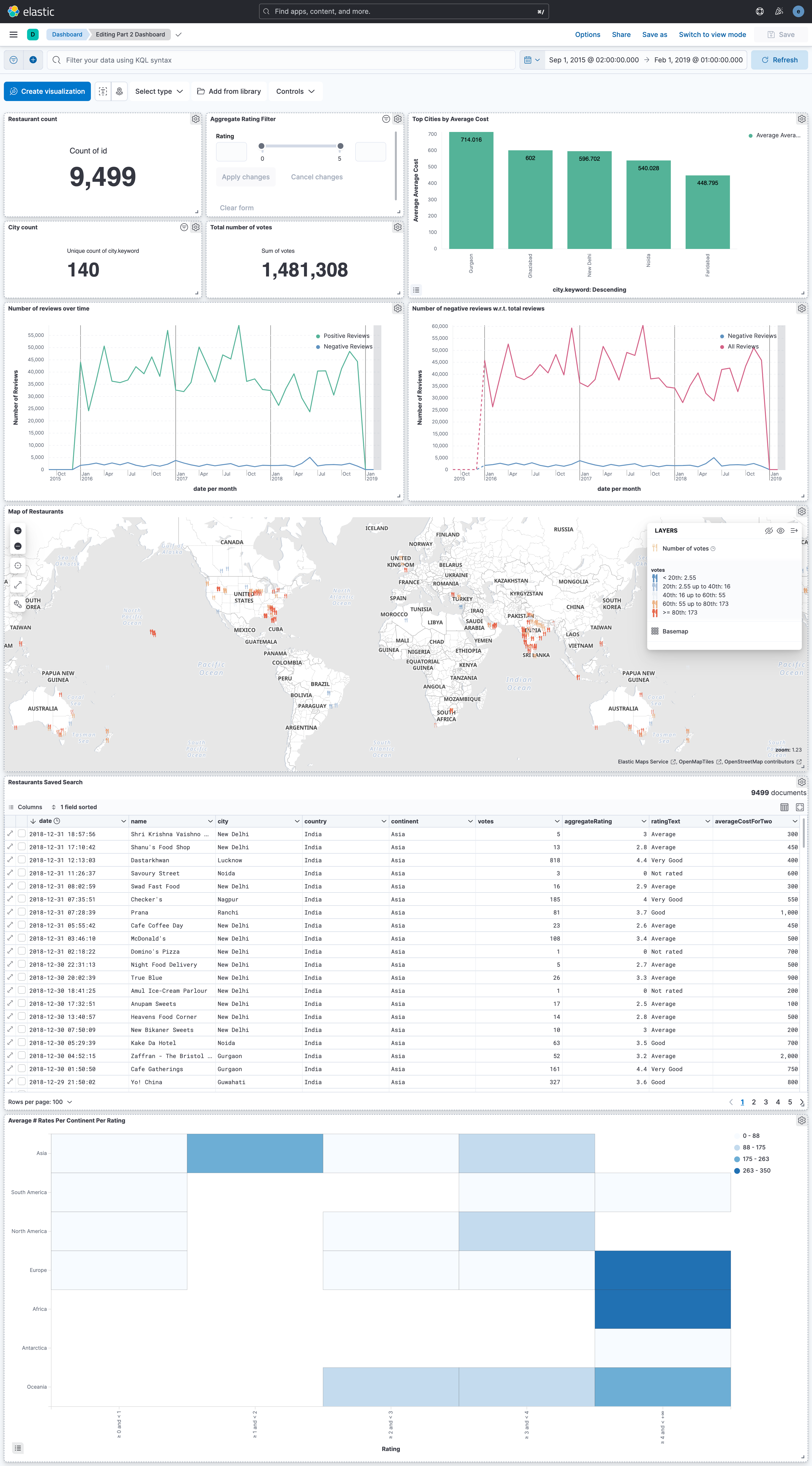
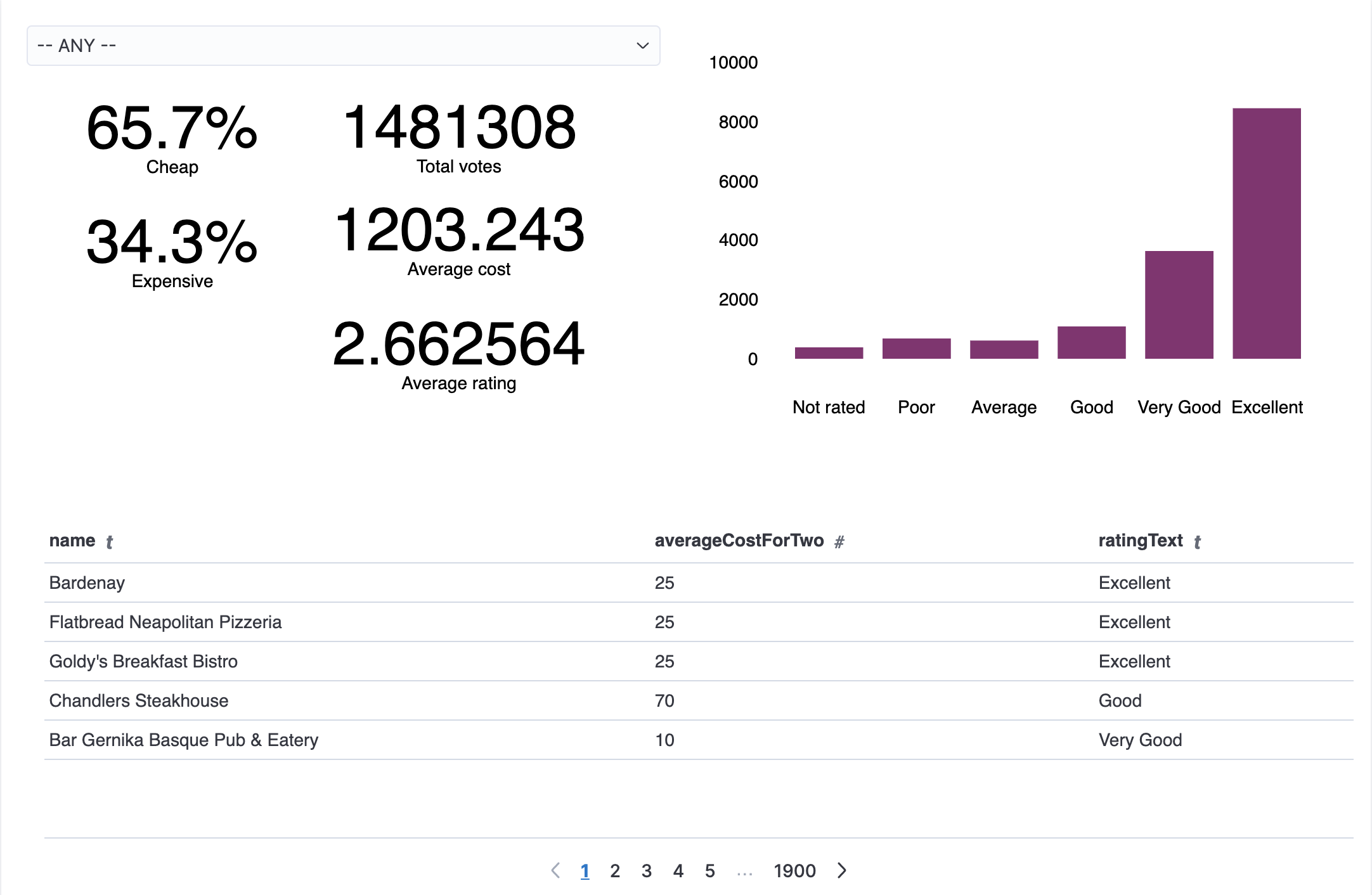
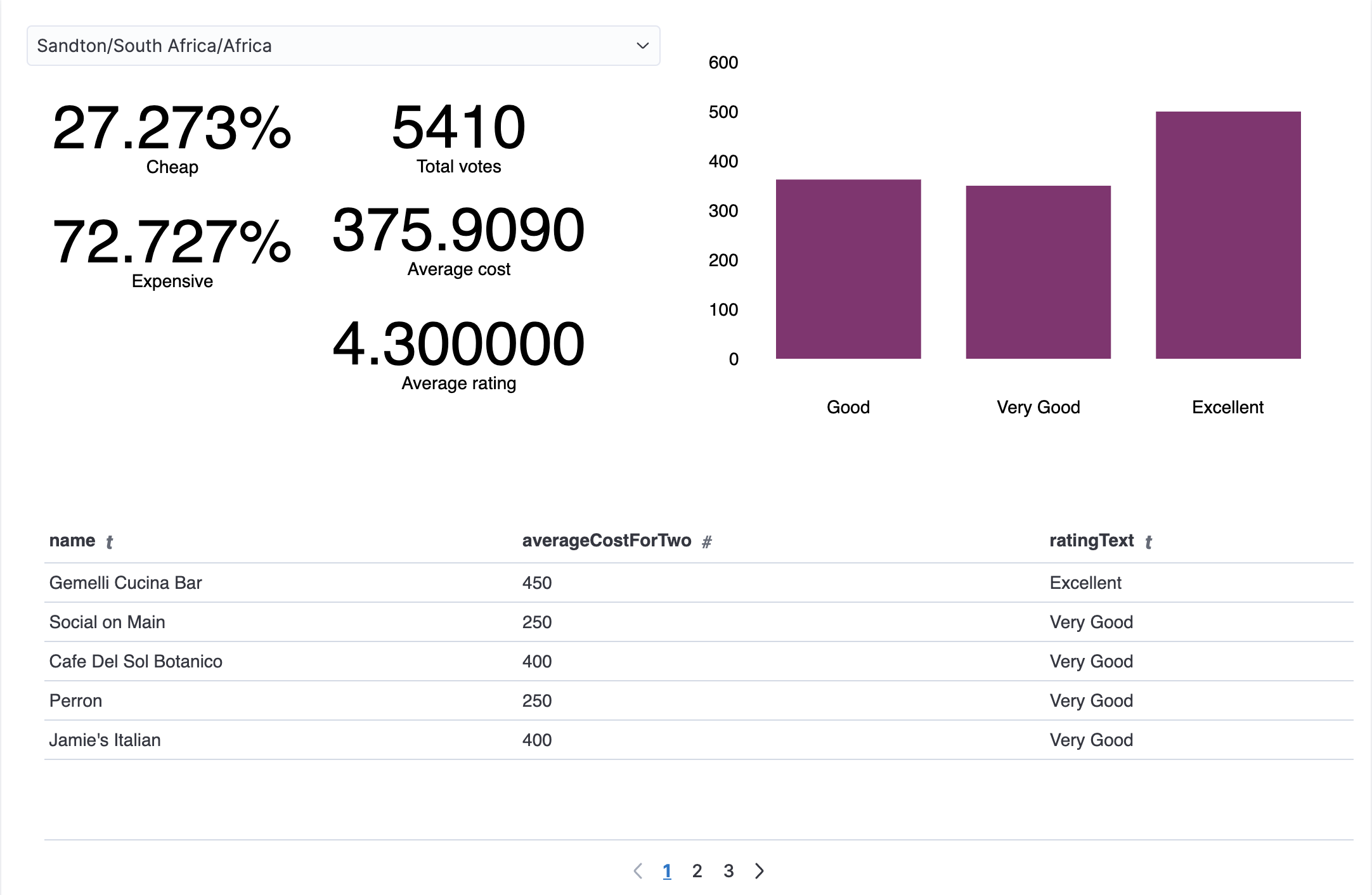
Data Visualization
The Dashboard, Canvas, and requested dependencies (like scripted fields and
stored searched) are stored in the JSON object export file export.ndjson.
Screenshot of the Dashboard and Canvas can be found below.
The scripted field continent_scripted has been generated with the following
Painless expression:
doc['cityRaw.keyword'].value.substring(doc['cityRaw.keyword'].value.lastIndexOf("/") + 1)
The expression extracts the last portion of the cityRaw field, i.e. the
portion of text between the last / and the end of the field, which contains
the continent.
Ingestion Plugin
Sources for the ingestion plugin can be found in the Gitlab repository:
usi-si-teaching/msde/2022-2023/visual-analytics-atelier/elasticsearch-plugin/ingest-lookup-maggicl.
The plugin can be built and installed on Elasticsearch with the script
./install-on-ec.sh included in the repository by changing the variable
ES_LOCATION to the path to the local installation of Elasticsearch.
The plugin works as illustrated in the README.md file in the repository, and
it has been tested with a unit test suite included in its sources.
The plugin lookup procedure works by splitting the indicated field in words (non-empty sequences of non-space characters -- according to the PCRE regular expression specification) and matching each word with the given substitution map, performing substitutions when needed.